内存管理和进程管理是操作系统的两大核心功能,二者密不可分,进程管理,除了做好 CPU 的调度,剩下的主要就是如何分配和管理进程内存。现代的操作系统主要还是基于请求分页(段)与虚拟内存进行内存分配和回收;而不管哪个操作系统,对内存都有基本的划分,例如 Text 段,Stack、Heap 等。但不同的编程语言与编译器会对内存做更细的划分,比如对 C 语言的粗略内存布局结构:
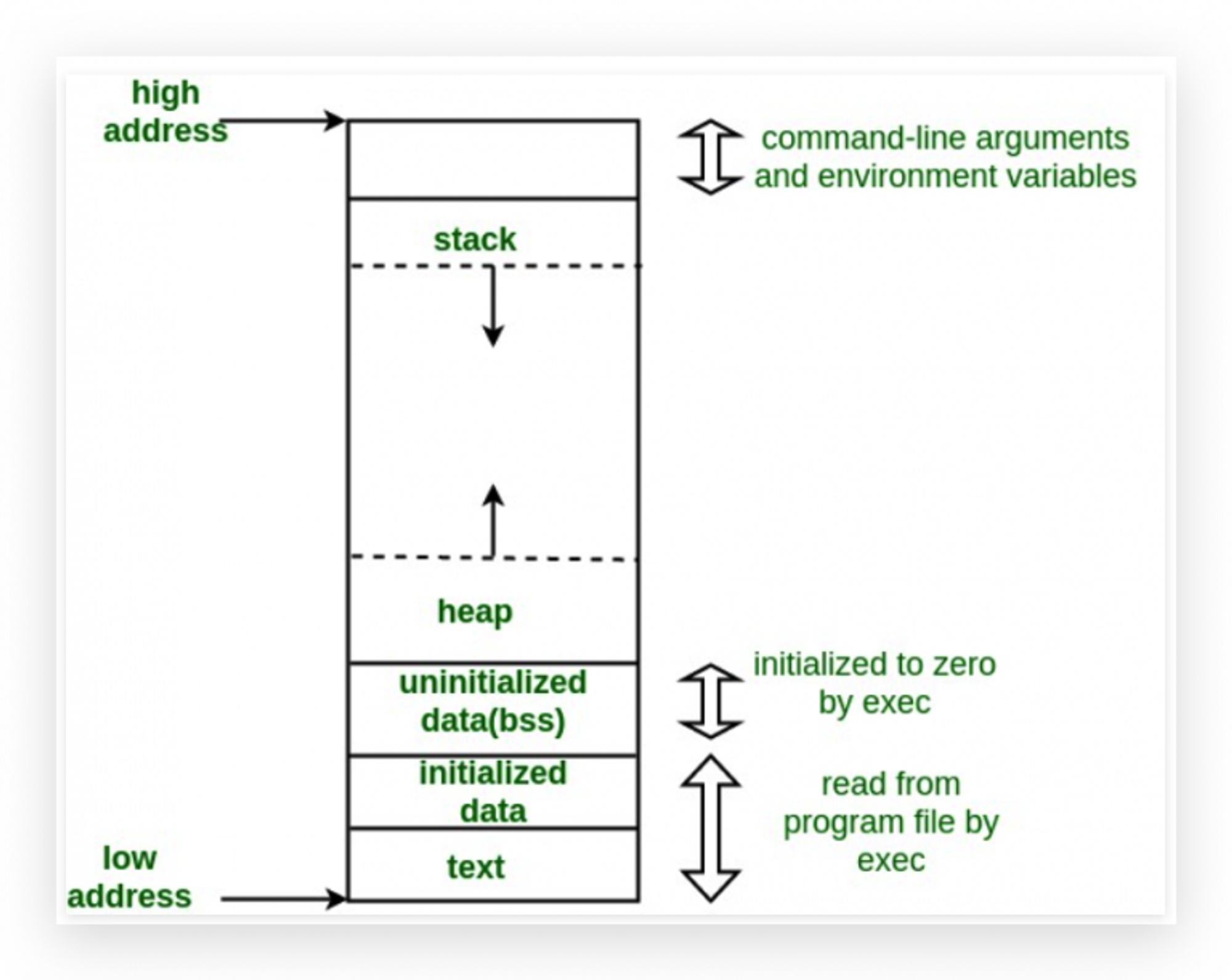
1:Text 段,主要是保存的是所有的函数指令,全局常量,该段为 read-only 段,不需要回写,所以整个程序执行过程中,该段会被优先调入内存,并且程序执行过程中可常驻内存。
2:Initialized Data 段,该段为数据段,主要保存全局的变量或者静态变量,还有常量指针;该段可以大致分为,read-only 和 read-write 两部分。
3:Uninitialized Data 段,又名 .bss(block started by symbol) 段,该段主要保存还未被初始化的全局变量,例如在
main 函数体外定义 int i;而且未设置初始值,i 变量会被保存在该段,且会被置 0 处理。4:Stack 段,即栈,主要保存函数调用中的寄存器值(函数形参,结果值,返回地址等),以及函数体内的 auto 零时变量等,栈一般从高地址向低地址生长。该段,随着函数调用自动进栈,出栈,具体是由栈指针
sp 完成,程序员无需管理内存。5:Heap 段,即堆,属于动态内存分配区域,malloc/realloc/free 进行内存管理。栈和堆在实际的内存中,会有很大的地址空间,其中一部分指向虚拟内存。
虽然大部分情况可以像上边那样,粗略分配内存;但事实上,在 Mac 平台,使用 Clang + LLVM 进行编译和链接,内存的每个段又会被划分为多个 section,例如 Text 段中会有
__cstring section(常量字符串区),__objc_classnmae section (类名区) 等等。稍后我们单步编译,检查汇编和 Mach-O 进行逐个分析。虽有有类似
https://github.com/gdbinit/MachOView这样优先的工具,但它并不能帮我们进行单步分析。事实上 Mac 本身提供了很多命令,帮助我们进行编译和查看 Mach-O 文件。clang size otool nm pagestuff vm_stat top vmmap xcrun...
这些命令都可以在终端通过
man clang,获得详细的帮助文档,如果你追求阅读体验,还可以直接在浏览器输入 x-man-page://clang 或者直接终端 open x-man-page://clang 就可以打开一个阅读体验更好的帮助文档,例如你可以尝试点击 clang help。Command + B 的过程
代码的编译过程,大致分为:
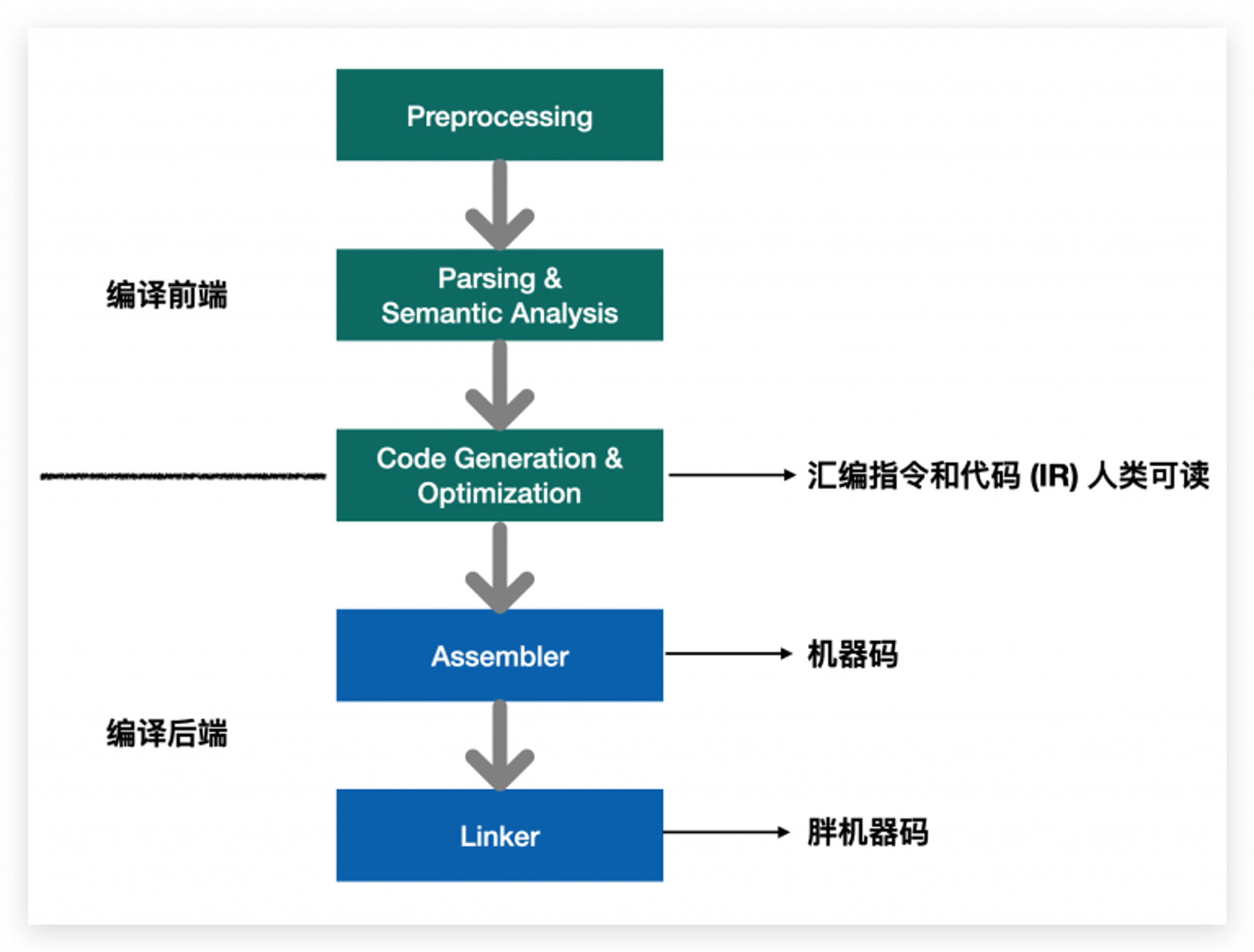
1: 预处理 主要是宏展开,include 头文件等。
2: 解析和语法分析 在预处理展开后,就可以对工程文件进行语法分析,报错和警告,就是在该阶段产生。该阶段的产物是抽象语法树 AST(Abstract Syntax Tree).
3:中间码生成与编译优化 这里的中间码指的是 LLVM IR (Intermediate Representation,IR),IR 是类似汇编的语言,即有 GNU Assembler 编译指令,也有汇编代码,IR 是强类型的精简指令集(Reduced Instruction Set Computing,RISC)。到这里,我们还有机会读汇编代码,因为下一步,就要对参考汇编指令,将汇编代码转为机器码,即二进制。
4: 汇编为目标文件 即将上一步的类汇编和优化后的产物装进目标文件,事实上目标文件也是二进制格式的文件,只不过都是单一的文件,相比于下一步的胖二进制文件,可以称为’瘦’二进制。通过
file 可以查看文件类型:$ file main.object main.object: Mach-O 64-bit object arm64
5:链接 将多个目标文件链接为多个目标文件或者动态库,生成
a.out 或者 Mach-O,即可执行文件$ file a.out a.out: Mach-O 64-bit executable arm64
整个编译 、汇编、链接的过程,都可以通过
Clang命令来完成,Clang 事实上是个小型驱动程序,自己并不真正的干活,而是通过控制编译、汇编、链接等工具进行工作。size 可以用来查看二进制文件的内存布局信息。我们先从最简单的 C 代码开始,通过下边的案例,弄清楚 static / const 类型的 auto 或者 global 变量以及函数,具体被存储到哪个 segment 的哪个 section,以及编译器的一些简单优化过程和函数调用的汇编代码简单分析。一、global 全局变量
main.c 文件的代码:int a = 90; int main() { return 0; }
为了让编译后的汇编尽量简单,
#include <stdio.h> 等先去掉。clang -S main.c -o main.as
上边的命令,会对 main.c 进行预处理和汇编,并输出 main.as。(这一步同样可以使用 Xcode -> Product -> Perform Action -> Assemble 完成,但会有很多汇编指令干扰阅读),浏览 main.as :
.section __TEXT,__text,regular,pure_instructions .build_version macos, 12, 0 sdk_version 12, 3 .globl _main ; -- Begin function main .p2align 2 _main: ; @main .cfi_startproc ; %bb.0: sub sp, sp, #16 .cfi_def_cfa_offset 16 mov w0, #0 str wzr, [sp, #12] add sp, sp, #16 ret .cfi_endproc ; -- End function .section __DATA,__data .globl _a ; @a .p2align 2 _a: .long 90 ; 0x5a .subsections_via_symbols
.section 是汇编指令,表示下边的指令属于哪个段,哪个 section,main 函数被完整的编入 __TEXT,__text 区域。sub sp, sp, #16 是汇编代码,sp 是栈指针,具体含义 sp = sp - 16 (字节为单位),需要注意 #16 并不是注释,表示的是立即数 16(即指令中的二进制本身就是参与运算的值,而非一个内存地址值)。main 函数之后,我们看到了全局变量 a 的相关汇编:.section __DATA,__data .globl _a ; @a .p2align 2 _a: .long 90 ; 0x5a
.section __DATA,__data 表示,DATA 段的,__data section,.p2align 2即 power of 2,2^2=4 字节内存对齐,.long 就是指 int。由此我们确切的看到了,全局变量 a 存入了 .section __DATA,__data 中。你可以在这里和这里 Arm 汇编文档查到汇编相关的信息。接下来用 size 命令看 a.out 的内存布局结构。clang main.c | size -m -x -l a.out
clang main.c 会自动生成 a.out (Mach-O),然后用 size 看内存结果 (使用 pagestuff 命令查看 Mech-O 也能获得类似的效果,并且能以逻辑分页的形式查看,这里使用 size 查看,输出较为简洁):Segment __PAGEZERO: 0x100000000 (zero fill) (vmaddr 0x0 fileoff 0) Segment __TEXT: 0x4000 (vmaddr 0x100000000 fileoff 0) Section __text: 0x14 (addr 0x100003fa4 offset 16292) Section __unwind_info: 0x48 (addr 0x100003fb8 offset 16312) total 0x5c Segment __DATA: 0x4000 (vmaddr 0x100004000 fileoff 16384) Section __data: 0x4 (addr 0x100004000 offset 16384) total 0x4 Segment __LINKEDIT: 0x4000 (vmaddr 0x100008000 fileoff 32768) total 0x10000c000
在
Segment __DATA: 下的 Section __data: 大小 4 字节,假如我们在 main.c 中增加全局变量 int b = 10;, Section __data:大小会变为 8 字节。括号中的虚拟地址并不是程序运行的物理地址,当程序真正被分配物理内存的时候,该地址会由地址转换单元转换为物理地址,大致的过程,确定该段分页的物理其实地址,以及页偏移地址,这些信息会保存到 PCB 中,等待内存真正被处理机调度时,页起始地址会被加载到页面基址寄存器中,方便快速计算真实物理地址。下一步,使用
otool 工具可以进一步查看 section 中的机器码,再确认一下我们的源码:int a = 90; int main() { return 0; }
使用 otool 查看
__DATA __data section :$ otool -s __DATA __data a.out a.out: Contents of (__DATA,__data) section 0000000100004000 0000005a
0000000100004000表示虚拟地址,0000005a 就是全局变量 a 的值,这里是 16 进制,5*16 + a = 90,16 进制中 a 表示 10(十进制)。二、static 全局变量
main.c 文件的代码:static int a = 90; int main() { return 0; }
继续使用刚才的命令(后续不再重复命令),为了方便,直接将结果输出到 GUI 上,同时通过
clang main.c重新生成a.out,方便查看。$ clang -S -o - main.c; clang main.c
打印输出后你会发现,在汇编代码中找不到变量 a 的相关信息。为什么这样呢?因为 static 限制了变量 a 并不是 global 类型,只作用于当前文件,编译器发现当前文件没有使用变量 a,所以不会进行任何编译,也不会进入最终二进制文件,这行代码相当于没写。这也告诉我们,如果全局变量不需要 global 类型,一定要加上 static ,这样即使变量没有被用到,而我们又忘了删除;编译器也会帮我们优化掉。
接下来,我们在 main 中使用 a。
static int a = 90; int main() { a = a + 10; return 0; }
重新编译,变量 a 再次出现,同样被保存在了
DATA __data 中.section __DATA,__data .p2align 2 ; @a _a: .long 90 ; 0x5a
如果我们把定义写在 main 中:
...... int main() { static int a = 90; a = a + 10; return 0; }
a 变量依然保存在
DATA __data 中,但是通过 @main.a 限制了作用域....... .section __DATA,__data .p2align 2 ; @main.a _main.a: .long 90 ; 0x5a
三、const (static) 常量与立即数优化
先来看 global 类型的常量
const int a = 90; int main() { int b = a + 10; return 0; }
编译后,我们会看到,常量 a 被直接存入了
Text 段的 __const section 中,这也比较好解释,a 不需要修改,而 Text 段也是只读段,程序运行中常驻内存(请求分页机制和虚拟内存技术中,DATA 段中的部分数据可能不在内存中,从而用到的时候需要从虚拟内存,实为磁盘的某个区域中加载),所以直接存入 Text 段会加快程序的执行效率。继续加上
static 修饰static const int a = 90; int main() { int b = a; return 0; }
编译后,我们找不到 a 变量;因为 a 变量不会被外部文件引用,也不需要改变,此时编译器会直接将 a 变量优化为立即数 #90,并存入寄存器 w8 中,这样即节省空间,又不需要额外的访存指令,执行非常高效:
...... mov w8, #90 ......
如果将
const int a = 90; 写入 mian 函数中,同样会被优化为立即数。所以如果变量不需要改变,都应该加上 const,如果不需要被外部文件引用,就应该加上 static const 修饰。四、未初始化的变量 uninitialized
对于为初始化的全局变量:
int a; int main() { return 0; }
编译后,会看到被存入
__common: Section 中(也叫开头提到的 bss section),并且用 0 填充(zerofill),所以 a 的值是 0,即使并没有手动初始化;该 section 在 DATA 段中:$ clang -S -o - main.c ...... .comm _a,4,2 ; @a $ size -x -m -l a.out ...... Segment __DATA: 0x4000 (vmaddr 0x100004000 fileoff 0) Section __common: 0x4 (addr 0x100004000 zerofill) total 0x4
五、auto 局部变量
int main() { int a = 90; int b = a + 10; return 0; }
对于局部变量,并不需要额外存储,因为局部变量只在函数内部使用,所以都会被直接当做立即数直接存入寄存器,如果发生嵌套调用(非叶过程),新进入的函数负责将当前的寄存器值压栈,即保存现场,然后将自己的局部变量放到寄存器上,进行运算。下面分析 main 函数的汇编代码
$ clang -S -fno-asynchronous-unwind-tables -o - main.c _main: ; @main ; %bb.0: sub sp, sp, #16 mov w0, #0 str wzr, [sp, #12] mov w8, #90 str w8, [sp, #8] ldr w8, [sp, #8] add w8, w8, #10 str w8, [sp, #4] add sp, sp, #16 ret
编译时,用参数
-fno-asynchronous-unwind-tables过滤一些汇编指令,方便阅读。sp 为栈指针,sub sp, sp, #16表示 sp = sp - 16(栈地址由高到低生长),开辟 16 字节的栈,供当前函数使用。我们关心的 a 变量的汇编代码为mov w8, #90,该指令将立即数 90 (变量 a 的值)存入寄存器 w8。str 是存字指令(store),ldr 为取字指令(load)。add w8, w8, #10 表示 w8 = w8 + 10,完成的是 int b = a + 10; 的操作。Arm 的通用寄存器有 32 个,X0-X31,都是 64位寄存器,但是可以通过 W 来表示寄存器的低 32 位值,w8 表示 64 位寄存器 X8 的低 32 位。上边的汇编代码看似进行了一番无意义的腾挪,实际函数的执行结果值和参数,都有固定的栈偏移位置,和寄存器来保存,猜测这样做,可以做方便实现流水线级别的函数汇编和执行。
目前的观察来看 w0-w7 是结果值 (value) 寄存器,w8-w15 为参数寄存器 (argu),至少在 mips 中是这样的,arm 也是 mips 的派生,所以做此猜测。当然对寄存器的使用,我这里是大致猜测,更多的汇编代码,可以参考:OS X Assembler Reference 以及 Arm Documentation 。
如果 a 变量没有初始化,会如何处理呢?
int main() { int i = 10; int a; int b = i + 10; return 0; }
编译器会按照变量顺序留下一个 4 个字节的栈空间给 a:
mov w8, #10 // int i = 10; str w8, [sp, #8] // w8 = [sp + 8]; ldr w8, [sp, #8] // int a = w8; add w8, w8, #10 // b = i + 10;
在 c 语言中,全局的未初始化变量会进行 0 填充,而这里的局部变量 a 并不会,而是直接将
sp + 8 留给 a。 a 具体的值就是sp + 8栈中之前的残留的值。六、const char * 与 char * const 以及 char arr[]
C 没严格意思上的字符串,但可以使用字符数组
char arr[]或者字符指针char *来实现。这两种定义字符串的方式在使用几乎没有区别,我们甚至完全把他们混着用,也没有问题。char * s = "hello world"; char arr[] = "this string"; int main() { printf("char of s: %c\n", s[0]); printf("char of s: %c\n", *(s + 1)); printf("char of arr: %c\n", arr[0]); printf("char of arr: %c\n", *(arr + 1)); return 0; }
但二者在赋值和内存分配上有很大区别,主要有两点,一是,字符指针指向的内容不可修改,而字符数组可以通过下标修改。
s[0] = 'a'; // 运行时报错 arr[0] = 'a';
为什么字符串声明为指针时不能修改,声明为数组时就可以修改?原因是系统会将字符串的字面量
Hello, world!保存在内存的__TEXT段, __cstring区,__TEXT段就是俗称的代码段,整个段都是函数指令和一些全局常量,并且__TEXT段为只读段,运行时系统只能访问,不可以修改。而指针变量s会被分开保存在__DATA段, __data区,这个区通常是可以修改的,所以可以修改指针变量s,让它指向新的内存,而*s实际指向的是__TEXT,__cstring区中的只读字面量,所以不可以修改。而声明为数组时,编译器会将数组变量和字面量一起保存在__DATA段, __data区,前面已经提到,这个内存区域是可以修改的。我们使用
clang命令查看内存布局,验证上面的结论。例如在main.c文件中同时定义字符指针和字符数组。char *s = "hello world"; char arr[] = "this string";
然后通过
clang命令进行编译。$ clang -S -fno-asynchronous-unwind-tables -o - main.c .section __TEXT,__cstring,cstring_literals l_.str: ; @.str .asciz "hello world" .section __DATA,__data .globl _s ; @s .p2align 3 _s: .quad l_.str .globl _arr ; @arr _arr: .asciz "this string"
但只有当
char *s和char arr[]都是全局变量时,上述情形成立。如果char *s和char arr[]都被定义为函数的局部变量。int main() { char *s = "hello world"; char arr[] = "this string"; return 0; }
此时无论是字符指针还是字符数组,它们的字面量都会被保存在
__TEXT,__cstring区中。那么既然__TEXT为只读内存段,此时系统如何实现对字符数组arr的元素修改呢? 答案是所有操作都基于栈来完成,因为局部变量都会被保存在栈上,函数执行完就会退出栈;所以针对字符数组,系统会专门开辟一个刚好容纳所以字符的栈空间,将整个字符串从__TEXT,__cstring区中读入栈中,如果需要修改字符数组中的某个字符,系统会通过某个通用寄存器暂存字符的ASCII码值,然后替换栈中对应的字节。但对于字符指针,如果修改其中的某个元素,系统会按照正常的访存操作执行,而__TEXT__cstring又是只读区域,所以运行时会报一个EXC_BAD_ACCESS的经典错误。为什么字符指针不能像字符数组一样进行字符串的栈拷贝?因为字符指针可以指向任意内存区域,如果将它所指向的字符串都拷贝到栈中,那么第一用多大的栈空间不确定,第二很容易由于指针指向错误,而导致不可预知的栈溢出。而字符数组,编译期间就保证了其长度固定,且是一个不能修改的左值,所以运行时系统可以放心的进行字符串的栈拷贝。
第二点区别,字符指针可以指向新的内存地址,而字符数组不可以。
s = "world"; arr = "world"; // 编译报错
为什么数组变量不能赋值为另一个数组?原因是数组变量所在的地址无法改变,或者说,编译器一旦为数组变量分配地址后,这个地址就绑定这个数组变量了,这种绑定关系是不变的。C 语言也因此规定,数组变量是一个不可修改的左值,即不能用赋值运算符为它重新赋值,通过编译报错,来阻止这种赋值。
C 语言通过
char arr[]和char *两种方式实现了不同字符串数据结构,字符数组是一串地址连续的地址空间,在物理上也是连续的,这样就可以支持随机访问,但又通过编译器阻止了用户任意的开辟连续地址空间,造成过多的内存碎片,所以如果确定数据长度,那么优先考虑用字符数组,这样性能更好。字符指针则是可以改变指向的地址,提供任意长度的字符串的存储。
char * s = "hello world"; int main() { s = "world"; return 0; }
但频繁的修改指针指向,会造成 TEXT 段的内存空间增大,因为每次重新赋值的字符串字面量,都会被保存都
__TEXT,__cstring段中。.section __TEXT,__cstring,cstring_literals l_.str: ; @.str .asciz "hello world" .section __DATA,__data .globl _s ; @s .p2align 3 _s: .quad l_.str .section __TEXT,__cstring,cstring_literals l_.str.1: ; @.str.1 .asciz "world"
上边的汇编指令中,
__TEXT,__cstring中既保存着“world”字面量,也保存着“hello world”字面量。为了提醒用户,字符串声明为指针后不得修改,可以在声明时使用const说明符,保证该字符串是只读的。
const char * s = "hello world";
这种方式是个提醒,相比不使用
const在内存布局上没有区别。而如果const修饰到指针s上,就不一样了。char * const s = "hello world";
此时指针变量
s也变成了常量,无法修改,在内存中,s会被存入.section __DATA,__const区,该区是只读区。.section __TEXT,__cstring,cstring_literals l_.str: ; @.str .asciz "hello world" .section __DATA,__const .globl _s ; @s .p2align 3
对于字符数组,如果加上
const。char const arr[] = "this string";
那么字符数组变量和字面量都会被一起存入
__TEXT,__const区中。.section __TEXT,__const .globl _arr ; @arr _arr: .asciz "this string"
七、static inline 函数
在 main.c 中额外增加一个函数 foo,并且在 main 中调用 foo:
void foo() { int a = 12 + 13; } int main() { foo(); return 0; }
通过上边我们已经知道,函数指令都会存入
Text 段的 __text section 中,这也是程序执行最重要的指令聚集地。.section __TEXT,__text,regular,pure_instructions .build_version macos, 12, 0 sdk_version 12, 3 .globl _foo ; -- Begin function foo .p2align 2 _foo: ; @foo ; %bb.0: ret ; -- End function .globl _main ; -- Begin function main .p2align 2 _main: ; @main ; %bb.0: sub sp, sp, #32 stp x29, x30, [sp, #16] ; 16-byte Folded Spill add x29, sp, #16 mov w8, #0 str w8, [sp, #8] ; 4-byte Folded Spill stur wzr, [x29, #-4] bl _foo ldr w0, [sp, #8] ; 4-byte Folded Reload ldp x29, x30, [sp, #16] ; 16-byte Folded Reload add sp, sp, #32 ret ; -- End function .subsections_via_symbols
将汇编简化一些:
_foo: ; @foo ...... _main: ...... bl _foo ......
可以看到,函数调用通过分支跳转指令
bl _foo 完成。这相比直接 pc + 4(pc 指程序计数器,执行当前正在执行的指令) 要慢一些,因为 pc + 4 很常用,会由专门的硬件电路实现。但如果遇到 bl _foo 跳转时,就不能用 pc = pc + 4 来寻找下一条指令。事实上这时会产生很多额外的工作。 1:先将当前的 pc 指针压栈,以确保 foo 函数执行完成后,能够跳回 main 函数。
2:经过译码器,将 foo 函数的入口地址给 pc。
C 为了极致优化,提供
inline 关键字,可以将 foo 函数的动作指令直接集成到 main 函数内(俗称内联展开),从而不需要指令跳转。但内联并不总是发生,即使写了 static inline,具体要看 foo 函数参数是否为常量值,且没有被多处使用。因为内联展开好比空间换时间,如果很多地方用了该函数,都内联展开,就会造成 Text 空间的冗余增长。所以当我们写下:static inline void foo() { int a = 12 + 13; } int main() { foo(); return 0; }
编译后,发现并没有被集成进 main 函数,依然是通过
bl _foo 分支跳转指令进行调用。因为 inline 展开可能需要额外的编译参数,已经相对周全的考虑,所以编译器不会轻易进行真内联,更多关于 inline 说明。不过我们可以给函数添加额外的编译说明 __attribute__((always_inline)):static inline void foo(void) __attribute__((always_inline)); void foo() { int af = 12 + 13; } int main() { int a = 101; foo(); a = a + 1; return 0; }
再次编译,文件中已经没有 foo 函数的汇编代码,foo 函数已经被内联展开到 main 中。
_main: ; @main ; %bb.0: sub sp, sp, #16 mov w0, #0 str wzr, [sp, #8] mov w8, #101 str w8, [sp, #4] mov w8, #25 // 手动注释: foo: int af = 12 + 13; str w8, [sp, #12] ldr w8, [sp, #4] add w8, w8, #1 str w8, [sp, #4] add sp, sp, #16 ret ; -- End function .subsections_via_symbols
其中
mov w8, #25 就是 foo 函数执行的代码,这就是内联后的效果,即不需要 bl __foo 跳转指令。更多
有了这些工具,以及对 C 的分析,下一步就可以分析 OC 的内存布局。待续…