翻译:Xiaobo 原文链接: Understanding memory reordering 推荐:之前读《程序员的自我修养》一书中有关于多线程的讲解非常好;但最近读到这几篇文章对于多线程的讲解,个人认为比前者(书)更加的清晰、易懂、全面。每篇文章的内容安排也很合理,非常感谢作者
TRIANGLES和他优秀的文章,这里是他的个人站点。相关系列译文
- 「译文」内存重排对无锁多线程的影响 (本篇)
译文正文部分
上一篇文章介绍了无锁多线程编程:多线程中的一种底层同步策略。无锁编程基于原子操作,与传统的互斥和信号量相比,无锁编程通过让 CPU 直接执行不能再细分的机器指令(即原子指令),来实现更加快速细微的同步机制。
显然,能力越大,责任就越大。无锁编程更加接近底层硬件,所以有必要了解一些底层硬件的工作机制。本文将会介绍无锁编程给软件和硬件带来的一些无法忽视的副作用,这也是一个很好的机会,让你惊叹于计算机内部小型化世界的复杂性。
内存重排
大多数的编程教程中都会告诉你:计算机会按照事先写好的程序片段依次执行指令,程序就是一段事先写好的操作文本,CPU 则按照该文本自上而下的进行执行。
惊喜的是,并不总是这样:计算机有能力根据自己的需要,去改变一些底层操作指令的顺序,特别是从内存中读取或写入的时候。这种奇怪的行为被称为内存重排,硬件和软件层面都会发生内存重排,目的往往是为了性能考虑。
内存重排是充分利用 CPU 空闲时间片的有效手段,能极大的提供程序执行效率。但另一方面,这也会给无锁编程带来一些干扰。
内存重排的基本机制
程序要被执行,就得加载到内存中(也叫主存储器,本段后文都用主存一词代替),CPU 的任务就是从主存中读取指令,然后运行,同时 CPU 也会根据需要,从主存中读取或写入一些数据。
CPU 主频不断地大幅提升,主存的读写访问速度却提升有限,一直跟不上 CPU 的发展速度,严重拖慢了程序的执行效率。举例来说,现代 CPU 在一纳秒内能完成 10 个指令的执行,但从主存中读取一条数据却需要几十纳秒!主存访问的速度就严重限制了 CPU 的发挥。为了解决这一问题,现代 CPU 的每个核心上都会设计一块自己的缓存存储空间,读写速度极快。
CPU 缓存用来存储常用的数据,从而避免 CPU 和主存的频繁交互。这样,CPU 需要数据时,首先从自己的缓存中拿,就无需被相对较慢的主存访问限制。
现代 CPU 大都是多核心 CPU,每个核心都有自己的一个缓存空间,用来和主存进行交互:
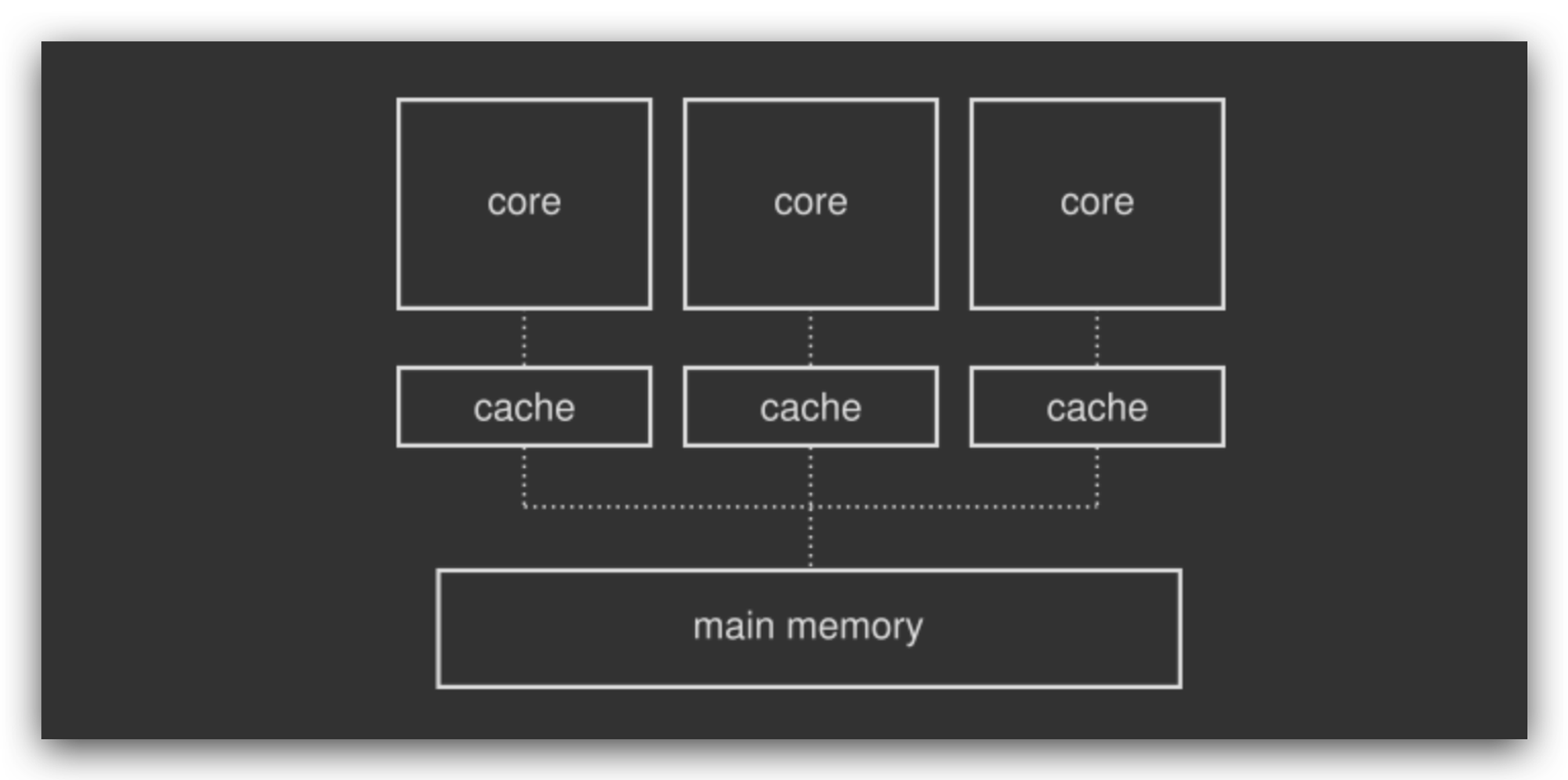
主存被多个CPU核心共享,CPU 的核心运算器直接和自己的缓存交互,缓存负责与主存交互,缓存是被特殊设计,访问速度基本无限制,这样就能充分发挥 CPU 的运算能力。
内存重排是一种优化手段
很明显,在多核心 CPU 环境下,CPU缓存增加了整体的复杂度。你需要清楚主存到 CPU缓存的数据传输细节,每块 CPU缓存彼此之间需要保证数据的一致性,这也被称为缓存一致性协议。某些情况下,这一设计则可能引发巨大的性能损耗,因此,工程师们想出了内存重新排序的技巧(还有许多其他技巧!),让每个核心都被充分利用。
内存重新排序可能发生的原因有几个。例如,假设两个内核被指示访问内存中的相同数据块。核心 A 从内存中读取,核心 B 向其写入。缓存一致性协议可能会强制核心 A 等待,而让核心 B 将其本地缓存数据先写入主内存,以便核心 A 可以读取最新的信息。等待的内核(A)可能会选择提前运行其他内存指令,而不是浪费宝贵的 CPU时间片而无所事事,尽管这样做会打乱你在程序中明确写下的操作指令的顺序。
当启用某些优化时,编译器和虚拟机也可以随意重新排序指令。这些更改发生在编译时,通过查看汇编或字节码可以很容易地发现。软件层面的内存重新排序也是利用了底层硬件可能提供的功能,目的是为了使代码运行得更快。
硬件层面内存重排的具体案例
来看下边的伪代码:
x = 0 v = false thread_one(): while load(v) == false: continue print(load(x)) thread_two(): store(x, 1) store(v, true)
假设,上述代码中,两个线程真正的并行在两个不同的 CPU 核心上,
load()和store()是两个原子操作。线程 1 在等待线程 2 把v置为true。自上而下,我们期望线程 1 被先执行,然后线程 2 被执行,最后打印1。但并不总是这样,也有可能打印出0。原因就在于,线程 2 中的代码指令有可能被重排:store(v, true) store(x, 1)
这样,
v先被置为true,然后再设置x为1。同理,线程 1 中的指令也有可能被重排,重排后,先打印x的值,后进行v的校验。内存重排对多线程的影响
在单核CPU上,硬件内存重排不会带来问题,单核 CPU 环境下线程是伪并行,此时多线程调度与切换的规则是被操作系统规定的软件结构。内存重排仍然可能发生,但前提是不能影响最终结果。指令的执行有一条基本原则:给定内核的内存访问在该内核看来和程序中编写的一致,也就是整体一致性。
但在多核环境下,会发生真正的并行,多个线程跑在多个不同的物理核心上,整体一致性就没有办法得到保证。然后就会出现像前文那样的代码案例。更别提,编译器和虚拟机也会进行内存重排。
通常,互斥锁和信号量这类加锁的同步机制,就是被设计用来避免内存重排引发的问题,无论内存重排是发生在软件层面还是硬件层面。毕竟加锁的同步机制往往是一套上层的同步工具。
但无锁的多线程方案更加接近底层硬件,它完全通过原子指令来实现多线程同步。但最后,这些原子指令很有可能被进行内存重排,打乱你精心设计的基于原子的同步机制。
如何解决内存重排问题
解决的办法就是通过内存栅栏(memory barrier),内存栅栏也是一种 CPU 指令,它可以让处理器按照预期的方式执行内存中的指令。就像路障一样,它能确保出现在栅栏前边的操作指令的执行,先于出现在后边的操作指令。
内存栅栏是一种硬件操作,直接和 CPU 交互。直接使用它,会破坏程序的可移植性。最好的办法是使用操作系统、编译器或者虚拟机提供的软件工具。
不过,软件小工具只是一个过渡阶段。让我们首先从软件和硬件两个层面,宏观的看一看系统中可能发生的所有内存场景,以便为问题建立一个清晰的脉络。过程中,你会发现构建内存模型(memory model)会有极大的帮助。
内存模型
这里的内存模型指的是一种抽象方法,用来指定内存中的哪些数据及指令可以被重排。处理器和编程语言对此都有实现,特别是它们都支持多线程的时候,所以内存模型既可以作用到软件层面,也能作用到硬件层面。
当系统非常谨慎的改变内存指令的顺序的时候,被称为遵循了强内存模型,相反,在弱内存模型环境下,你将看到各种疯狂的内存重排。x86 系列的处理器就遵循了强内存模型,而ARM 和 PowerPC 系列的处理器遵循的是弱内存模型。这些都是硬件层面的内存模型。
软件层面内存模型的好处
很明显,硬件层面的内存模型已经被封锁在 CPU 的引擎盖下边了。而软件层面的内存模型则没有,你可以根据自己的需要选择对应的内存模型,特别是当你需要实现无锁编程的时候。
例如,编译器可以被指定使用强内存模型进行编译,这样就可以放心的使用原子操作来实现多线程的同步机制。根据你的要求,编译器会结合使用内存栅栏确定出最优的内存模型,而不用考虑底层硬件是不是使用了弱内存模型。同时,它也会兼顾软件层面的内存重排操作。所以,使用软件层面的内存模型可以有效的屏蔽底层硬件的各种细节。
基本上,所有的编程语言都实现了一个内存模型,即它们根据特定的规则在内部处理内存。有些编程语言不会直接提供,因为它们不直接处理多线程。其他一些像 java、Rust 和 C++,则直接提供了一些工具来控制内存重新排序行为,如上面所述。
内存模型在实现上的微调
强·弱内存模型只是一种理论阐述,真正实现的时候,编程语言通常会提供 3 中内存模型的方式,来控制内存重排。
1)顺序一致性
最没有侵入的内存重排,就是不使用内存重排。这也是强内存模型第一种实现,称为顺序一致性。这种方式,很显然能完全解决无锁编程的各种问题。因为不存在内存重排,程序的执行就会和你所写的代码顺序完全一致。
顺序一致性内存模型,还有另一个特性,用来确保多线程在多核心 CPU 上的并行执行的顺序。它会强制要求整体一致性(上文提到的),即所有的 CPU 核心在执行多线程指令时,整体上保持顺序性。我们通过下边的代码示例,来进一步解释:
x = 0 y = 0 thread_A: store(x, 1) thread_B: store(y, 1) thread_C: assert(load(x) == 1 && load(y) == 0) thread_D: assert(load(x) == 0 && load(y) == 1)
暂且忘记内存重排这一事实,来宏观的看上述代码。假设线程的执行预期的顺序是:A-C-B-D,那么如果线程 C 看到的就是
x==1 和 y==0,那么断言通过,表示线程 C 的执行确实是在 A 之后,B 之前。在顺序一致性的模型下,线程 D 的断言则会失败。因为顺序一致性要求,线程 C 和 D 看到执行顺序应该是一致的,即总是先执行 A 后执行 B。上边的理解,可以看做是凭着直觉去模拟多线程的执行。然而,事实上,顺序一致性会禁用所有软件和硬件潜在的内存重排。这就会带来严重的性能瓶颈。尽管如此,顺序一致性也是有必要的,特别是在多消费者-多生产者的环境下,所有消费者对生产者的观察必须保证顺序性。
2) Acquire-release 内存排序
Acquire-release 内存排序是一种介于强和弱之间的内存模型。它和顺序一致性工作模式类似,区别在于,它不要求整体一致性。我们回看上边的代码示例,在
Acquire-release模式下,线程 D 被允许看到和线程 C 不一样的顺序,所以 D 的断言很有可能通过。Acquire-release模式通过让多线程共用同一个特殊的原子变量,来提供同步机制。拿上边的例子来说,线程 A 和 C 通过同一个原子变量,来保证线程 C 在线程 A 执行完执行。但y值并不在同步机制里,对于y的操作可以随意的被重排。具体来说,支持
Acquire-release模式的编程语言都会提供acquire和release两个关键字用来标记内存的访问。线程 A 通过原子操作store来写入一个值到共享变量里,线程 B 则通过原子操作load读取该共享变量,如果线程 A 上的store被标记为release,线程 B 上的laod被标记为acquire,这时就能确保线程 B 看到线程 A 的所有内存指令都是没有被重排的符合顺序一致性的事件序列。看上去有些烧脑,但其实正是互斥的基本原理,acquire和release都是来自互斥里的术语(mutex jargon)。3) Relaxed ordering 自由重排
这属于弱内存模型的一种,使用该模式,表示你一点不会关心内存重排。编译器和处理器为了优化程序执行效率,会随意的重排内存。当然原子操作依然是完整的,所以这种模式适合只保证共享数据的完整性,不在乎顺序,所以也不能作为保证多线程安全的一种机制,但该模式下,能提供程序的执行效率。
(全文完,该系列译文完结!)