什么是机器学习?
什么是机器学习,目前并没有明确的学术定义,一般有两个比较认可的定义:
1: 人工智能领域的先驱 Arthur Samuel :一种在没有明确的编程下,使计算机具有学习的能力。
2:另一位计算机人工智能领域的科学家 Tom Mitchell 做出了更为学术的解释:机器学习程序,能够通过历史的经验(E),分析预测出特定任务(T)的未来值,并且提供对这个预测值的准确率(P)。这种定义强调了三点 E T P:
历史数据(经验) E : Experience 目标任务 T: Task 正确率 P : Probability
比如,通过机器学习对某城市的房价进行预测,那么有大基本模型:
E: 过去几年的房价数据,数据划分的维度没有限制,可以是房屋面积,地理位置,小区环境等都可以作为 E. T: 预测来年的房屋价格。 P: 房价预测准确的概率。
一般来讲,任何一个机器学习问题,都可以分为两类:
1:有监督学习 (supervised learning) 2:无监督学习 (unsupervised learning)
有监督学习
总体来说,有监督学习,有两个特点,有确定的数据集合作为输入,对于输出,我们已经有了明确的预期来对结果进行评判。有监督学习又可以分为两类:
回归 (regression) 分类 (classification)
对于回归问题,预测的结果是相对于连续的输出,意味着函数图形逼近连续的曲线(例如,假设房价的走势图逼近 y = kx + b);而分类问题,预测的结果只有几种离散的值 (明天会不会下雨,答案只有两种:会 / 不会)。
例如:
回归问题:通过某人的自拍照,预测他的年龄,年龄区间可以是 1-100 或更多,也可以是 50.5 岁等,总之结果可以是一个近似的连续函数。 分类问题:对病人的肿瘤进行分析,得出是良性的(benign)还是恶性的(malignant)。结果只有这两种可能。
无监督学习
对比有监督学习,无监督学习最大的特点,就是对于结果,没有明确的预期。另外输入的数据集也没有明确的来源和要求。机器学习算法能自己通过数据源的结构,或者数据之间的关系自动分簇。我们只需要结果,并不对结果做出任何反馈(比如判断正误)。无监督学习也可分为集群(clustering) 和 非集群(non-clustering) ,但大部分情况无需严格区分这两种问题。
例如:
集群:收集1000000个不同的基因,并找到一种方法来自动将这些基因分组,可以按照基因在某种程度上相似度分组,如寿命、位置、角色等。具体用哪个标准划分,完全有机器学习算法根据数据的结构划分,划分的结果种类中,很有可能是我们以前没见过的。非集群:“鸡尾酒会算法”允许你在混乱的环境中找到结构。在鸡尾酒会上从一系列声音中识别出个人的声音和音乐。
机器学习的基本模型表示
下图表示了一个机器学习模型的数据处理过程:
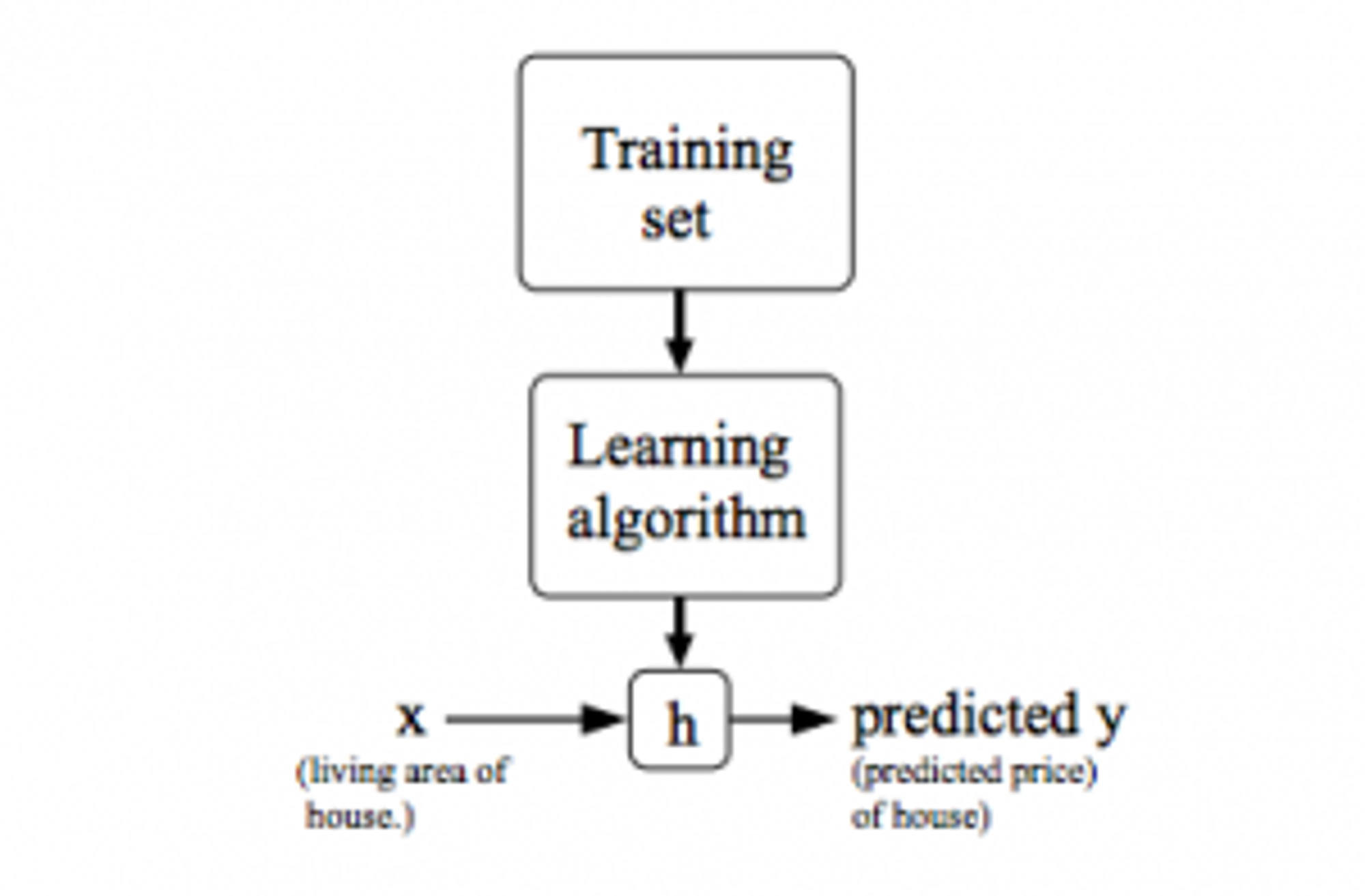
为了方便理解,这里还以预测房价举例, 1:输入训练的数据 上边的数据称为
Training Set,将这些数据交给机器学习算法,进行训练。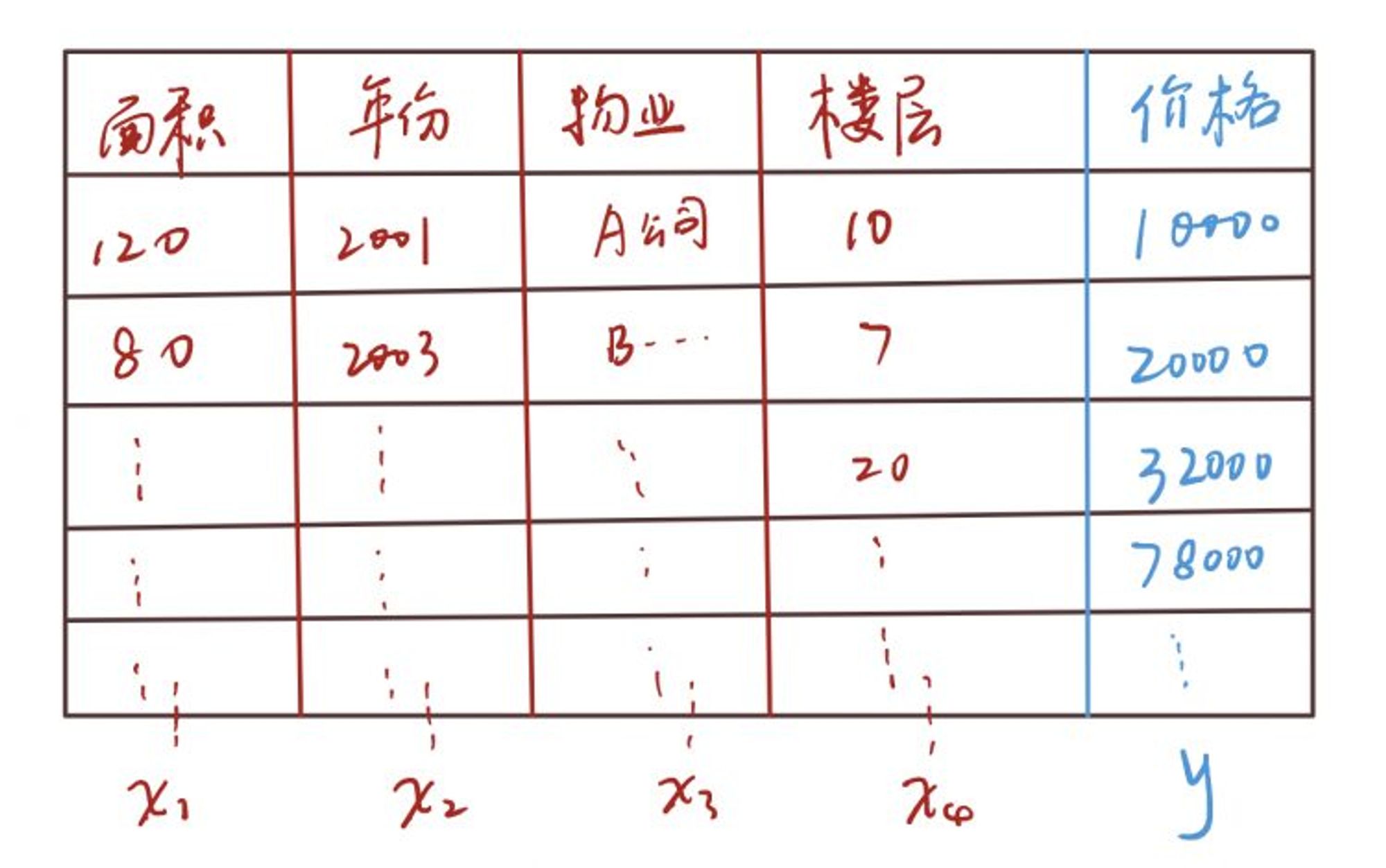
2:训练的目的是为了得到一个假设函数 h(x) (hypothesis),假设采用线性回归进行训练,训练的结果是:
x1 表示的就是数据集中的 x1,即房屋面积,x2 和 x3 以此类推。其实算法真正要得到的是 h(x) 函数的系数,即 (500, 2, 10, 101, -73),当然这里只是举例。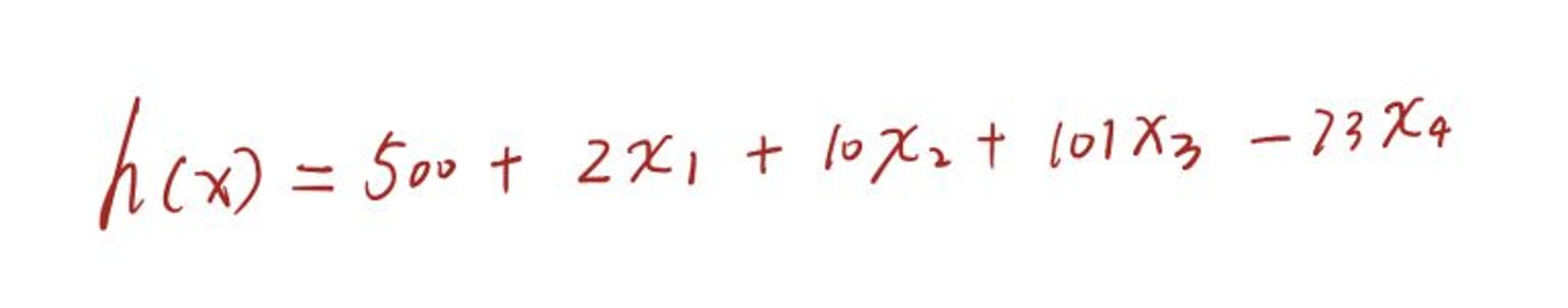
3: 有了
h(x),只需要给定一个的 X 值,就可以预测出一个结果,这个结果就是预测的房屋价格。这里的 X 表示的是向量或者 1*4 矩阵 [x1, x2, x3, x4]。个人觉得,机器学习是个很有趣味的领域,在这里,以前学习的
微积分和线性代数和概率论会得到充分的利用。比如线性回归算法中,用到的函数的梯度、偏导数、矩阵运算等。下一节将围绕线性回归展开记录。