这是第二篇,第一篇解刨操作系统虚拟内存一已经详细的介绍了虚拟内存已经计算机内存管理的基本概念。本篇将重点结合XNU内核源码、部分dyld和cctools源码进行深入探测虚拟内存。为了结构清晰,我会尽量避免贴大段的源码,如果有需要可自行下载上述三个源码库,结合阅读。
问题
1: 虚拟内存与 Mach-O 文件的关系 ?
2: 虚拟内存是如何被构建出来的?
3: 什么是 ASLR,已经如何计算它 ?
4: 什么是 COW ?
5: 到底什么是内存映像(Image) ?
6: 进程启动的主要流程 ?
关于 Mach-O 文件
由于 Mach-O 文件并不是凭空来的,它是由源代码经过编译和链接生成的。如果不熟悉相关问题,建议阅读:
2: 链接-Linking
Mach-O 的整体结构
关于Mach-O的结构一眼就看完了,主要有三部分:
1: Header 头部信息,主要包含指令集类型、commands 段的大小等。
2: Load Commands,这部分在程序装载的时候使用,内核通过它映射出虚拟内存的
__TEXT、__DATA段。 3: 具体的数据,这部分数据,在需要的时候,会被装载进入内存。
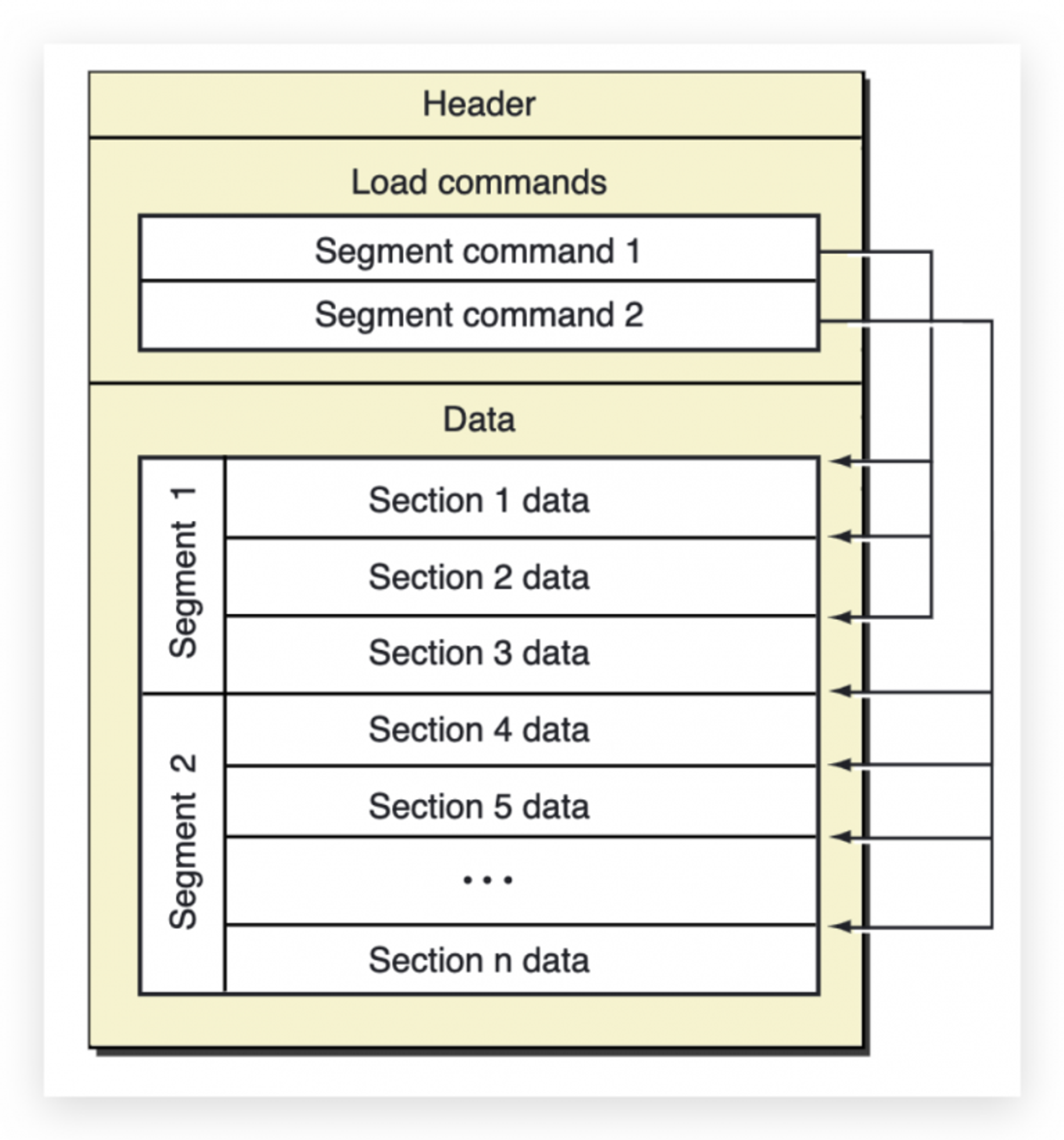
除了使用 MachOView,还可以使用
otool -v -h a.out或者size、objdump等等命令更细致的查看Mach-O 文件,同样这些在我之前的文章里已经详细介绍过。苹果官方的Mach-O文档已经被标记为过期,另外 Github 上有一些对丢失的苹果官方Mach-O相关文档的备份,可供查阅。代码总览
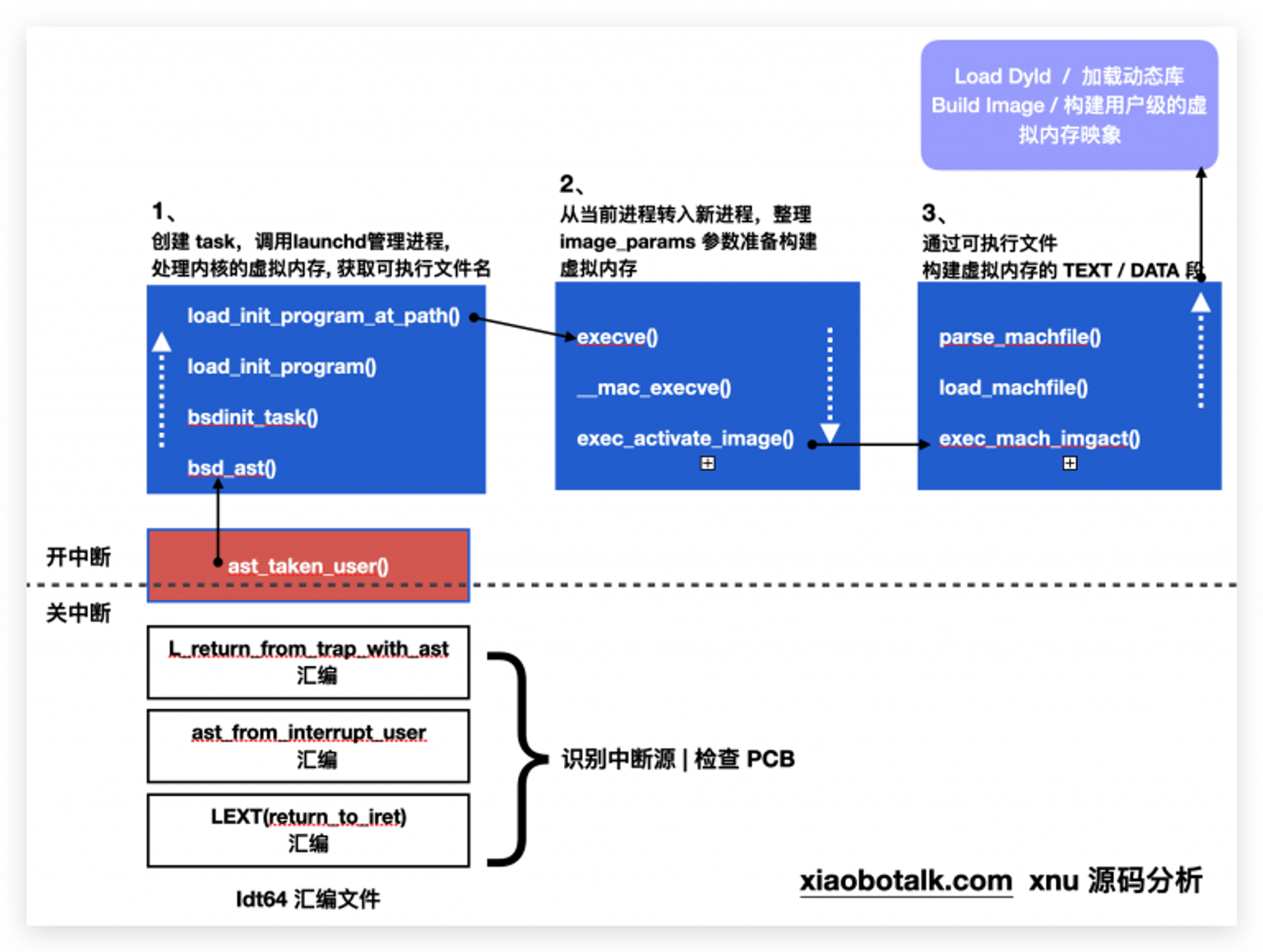
进入正题,xnu 内核源码中关于装载程序到跳转到 dyld 部分的工作,主要可以概括为两个方面:
1、处理(构建)新的进程和task,因为新的进程是从父进程继承下来的,所以说构建可能不太准确。 2、构造虚拟内存
vm_map。忽略掉进程相关的处理工作,甚至可以认为整个程序启动过程主要就是在构建虚拟内存,即使到了 dyld 中加载相关动态库,其实也是在构建虚拟内存。所以虚拟内存很重要。xnu 的代码非常多,下图是我做的一个图示,如果需要阅读源码,可以参考。
进程相关
进程相关的处理,并不是文章的重点,但是也非常长和复杂,这里做一些简单的说明。如果看源码,追溯 C 函数的调用,你会发现到
ast_taken_user函数就无法再往前找,事实上ast_taken_user是被汇编函数调用的,这些汇编写在idt64.s汇编文件中,一直找到汇编函数LEXT(return_to_iret),发现无法继续在xnu的源码中找到LEXT(return_to_iret)入口。由于这些汇编比较难读,这里只能做一些大概的推断。从汇编代码来看,
LEXT(return_to_iret)是在每个CPU时钟周期结束时自动执行,目的是检查是否有中断需要处理,下边是部分源码:decl %gs:CPU_INTERRUPT_LEVEL TIME_INT_EXIT /* do timing */ movq TH_PCB_FPS(%rax),%rax /* get pcb's ifps */ /* Load interrupted code segment into %eax */ movl R64_CS(%r15),%eax /* assume 64-bit state */ cmpl $(SS_32),SS_FLAVOR(%r15)/* 32-bit? */ testb $3,%al /* user mode, */ jnz ast_from_interrupt_user /* go handle potential ASTs */
可以大概推测,首先检查了 PCB 相关信息,主要看是否有新的进程需要处理,如果有,将中断信息保存,然后通过
ast_from_interrupt_user检查是否需要处理来自用户态的中断信息。ast_from_interrupt_user: testl %eax,%eax /* pending ASTs? */ je EXT(ret_to_user) /* no, nothing to do */ jmp L_return_from_trap_with_ast /* return */
ast应该是Asynchronous System Trap的缩写,异步的系统陷入,也就是中断。检查到如果有需要处理的用户态中断,调用L_return_from_trap_with_ast函数,该函数收集所有的用户态中断信息,并保存,最后调用ast_taken_user这个 C 函数来分发中断处理。// handle all ASTs (enables interrupts, may return via continuation) CCALL(ast_taken_user)
以上操作都是在关中断状态下进行的,这样防止被其他中断打断当前的执行。在
ast_taken_user()函数中,先分发需要在关中断状态下执行的中断处理,然后执行开中断。// 开中断 ml_set_interrupts_enabled(TRUE)
接着处理其他非关中断下执行的中断处理,例如 AST_BSD 中断。
if (reasons & AST_BSD) { thread_ast_clear(thread, AST_BSD); bsd_ast(thread); }
随后就进入到 BSD 层,开始并不会真正的创建新的进程,首先会基于当前进程的一个线程,创建 task,设置
dtrace相关的跟踪信息。在 macOS 和 iOS 上管理进程的进程是launchd,进程 id 是 1,其他进程相当于该进程的子孙进程。所以内核程序会根据不同的环境调用不同的launchd。static const char * init_programs[] = { #if DEBUG "/usr/appleinternal/sbin/launchd.debug", #endif #if DEVELOPMENT '' DEBUG "/usr/appleinternal/sbin/launchd.development", #endif "/sbin/launchd", };
随后在
execve函数和__mac_execve以及exec_activate_image中,会整理一个庞大的镜像参数结构体image_params,该结构体定义在bsd->sys->imgact.h中。其中包含了二进制文件名,一页的二进制文件内容(主要是 header),文件描述符等,还有很多地址空间的信息。struct image_params { user_addr_t ip_user_fname; /* file name */ .... struct vnode *ip_vp; /* file */ struct vnode_attr *ip_vattr; /* run file attributes */ struct vnode_attr *ip_origvattr; /* invocation file attributes */ cpu_type_t ip_origcputype; /* cputype of invocation file */ cpu_subtype_t ip_origcpusubtype; /* subtype of invocation file */ char *ip_vdata; /* file data (up to one page) */ int ip_flags; /* image flags */ int ip_argc; /* argument count */ int ip_envc; /* environment count */ int ip_applec; /* apple vector count */ .... }
在
exec_activate_image函数中还会真正独立出一个新进程,还会处理和复用一些从父进程继承下来的地址空间。关于这部分,源码中有较为详细的注释说明:/* * For execve case, create a new task and thread * which points to current_proc. The current_proc will point * to the new task after image activation and proc ref drain. * * proc (current_proc) <----- old_task (current_task) * ^ ' ^ * ' ' ' * ' ---------------------------------- * ' * --------- new_task (task marked as TF_EXEC_COPY) * * After image activation, the proc will point to the new task * and would look like following. * * proc (current_proc) <----- old_task (current_task, marked as TPF_DID_EXEC) * ^ ' * ' ' * ' ----------> new_task * ' ' * ----------------- * * During exec any transition from new_task -> proc is fine, but don't allow * transition from proc->task, since it will modify old_task. */
虚拟内存的创建
经过漫长的处理,终于来到了
load_machfile和parse_machfile函数,这里是真正创建虚拟内存的地方,首先会创建 pmap 对象 和 vm_map 对象,实际都是结构体,vm_map 就是进程的虚拟内存,内部会持有一个 pmap 对象,pmap 负责持有页表和 TLB 快表,以及进行地址转换。创建虚拟内存的函数vm_map_create内部,会进行虚拟内存大小的限制:if (max_mem > 0xC0000000) { // Max offset is 13.375GB for devices with > 3GB of memory max_offset_ret = min_max_offset + 0x138000000; } else if (max_mem > 0x40000000) { // Max offset is 9.375GB for devices with > 1GB and <= 3GB of memory max_offset_ret = min_max_offset + 0x38000000; } else { // Max offset is 64GB for pmaps with special "jumbo" blessing max_offset_ret = MACH_VM_MAX_ADDRESS; }
若物理内存是 3GB 内存,虚拟内存限制在 13.375 GB;若物理内存大于1GB,小于3GB,虚拟内存限制为9.375GB。兜底的大小是 64GB 的虚拟内存。同时还会设置分页的大小:
if (is_64bit '' page_shift_user32 == SIXTEENK_PAGE_SHIFT) { /* enforce 16KB alignment of VM map entries */ vm_map_set_page_shift(sub_map, SIXTEENK_PAGE_SHIFT); } #if __arm64__ '' (__ARM_ARCH_7K__ >= 2) #define SIXTEENK_PAGE_SIZE 0x4000 #define SIXTEENK_PAGE_MASK 0x3FFF #define SIXTEENK_PAGE_SHIFT 14 #endif /* __arm64__ '' (__ARM_ARCH_7K__ >= 2) */ #define FOURK_PAGE_SIZE 0x1000 #define FOURK_PAGE_MASK 0xFFF #define FOURK_PAGE_SHIFT 12
64 位,页面大小 16KB,14个bit位,32 位下是 4GB,12个bit位。这里定义好了页面大小的掩码
0x3FFF,方便进行业内地址偏移的计算。在load_machfile函数中,还会提前计算好ASLR(地址空间布局随机数),一个可执行文件的,一个是动态库的。为了不打断源码思路,关于ASLR后文会详细分析。随后进入
parse_machfile函数,通过Mach-O的header中的ncmds可以知道具体有多少条Load Commands,Load Commands会被映射到内核内存中,然后通过循环ncmds,依次读入Load Commands来映射二进制文件。在结构上,一个Mach-O中的Segment,对应一个vm_object结构体,内部会包含然后vm_page结构体,这些vm_page会进行 16KB对齐(64位机器)。所有的
vm_object被vm_map用双向链表管理:struct vm_map_links { struct vm_map_entry *prev; /* previous entry */ struct vm_map_entry *next; /* next entry */ vm_map_offset_t start; /* start address */ vm_map_offset_t end; /* end address */ }; typedef struct vm_object *vm_object_t; typedef union vm_map_object { vm_object_t vmo_object; /* object object */ vm_map_t vmo_submap; /* belongs to another map */ } vm_map_object_t; struct vm_map_entry { struct vm_map_links links; /* links to other entries */ #define vme_prev links.prev #define vme_next links.next #define vme_start links.start #define vme_end links.end struct vm_map_store store; union vm_map_object vme_object; /* object I point to */ ...... }
vm_page 由 vm_object 用一个双向链表管理
// vm_page.h 头文件 typedef struct vm_page *vm_page_packed_t; struct vm_page_packed_queue_entry { vm_page_packed_t next; /* next element */ vm_page_packed_t prev; /* previous element */ }; typedef struct vm_page_packed_queue_entry vm_page_queue_chain_t; struct vm_page { union { vm_page_queue_chain_t vmp_q_pageq; /* queue info for FIFO queue or free list (P) */ struct vm_page *vmp_q_snext; } vmp_q_un; vm_page_queue_chain_t vmp_listq; /* all pages in same object (O) */ ... }
这部分的图示: 地方有限,该图并不能完整的表示所有的结构关联,例如一个 vm_map_entry 中既可以是 vm_object,也可以是另一个 sub vm_map。另外一个 vm_object 会包含若干个 vm_page 图中也没有画出来。需要强调在Mach-O文件中,除了
header与Load Commands,其他都没有读入内存,只是做了地址映射。虚拟地址和二进制文件中的文件偏移差值相等。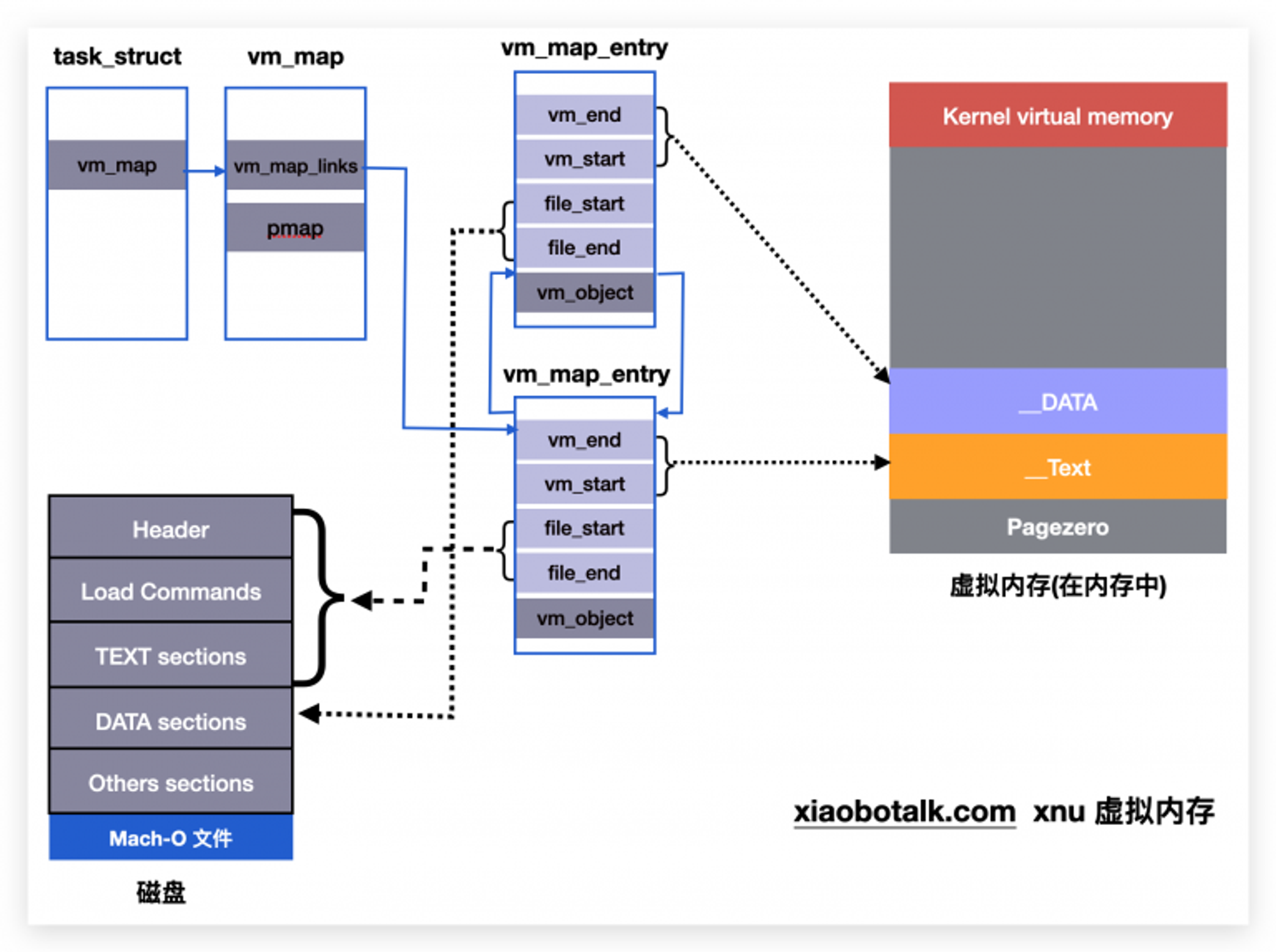
vm_end = vm_start + (file_end - file_start)
只有当程序真正运行,需要读内存的时候,才会把对应的内容读入到内存,另外每一个虚拟内存段创建的时候,都会加上 ASLR 的偏移值,这里先不讨论,后面专门讨论。
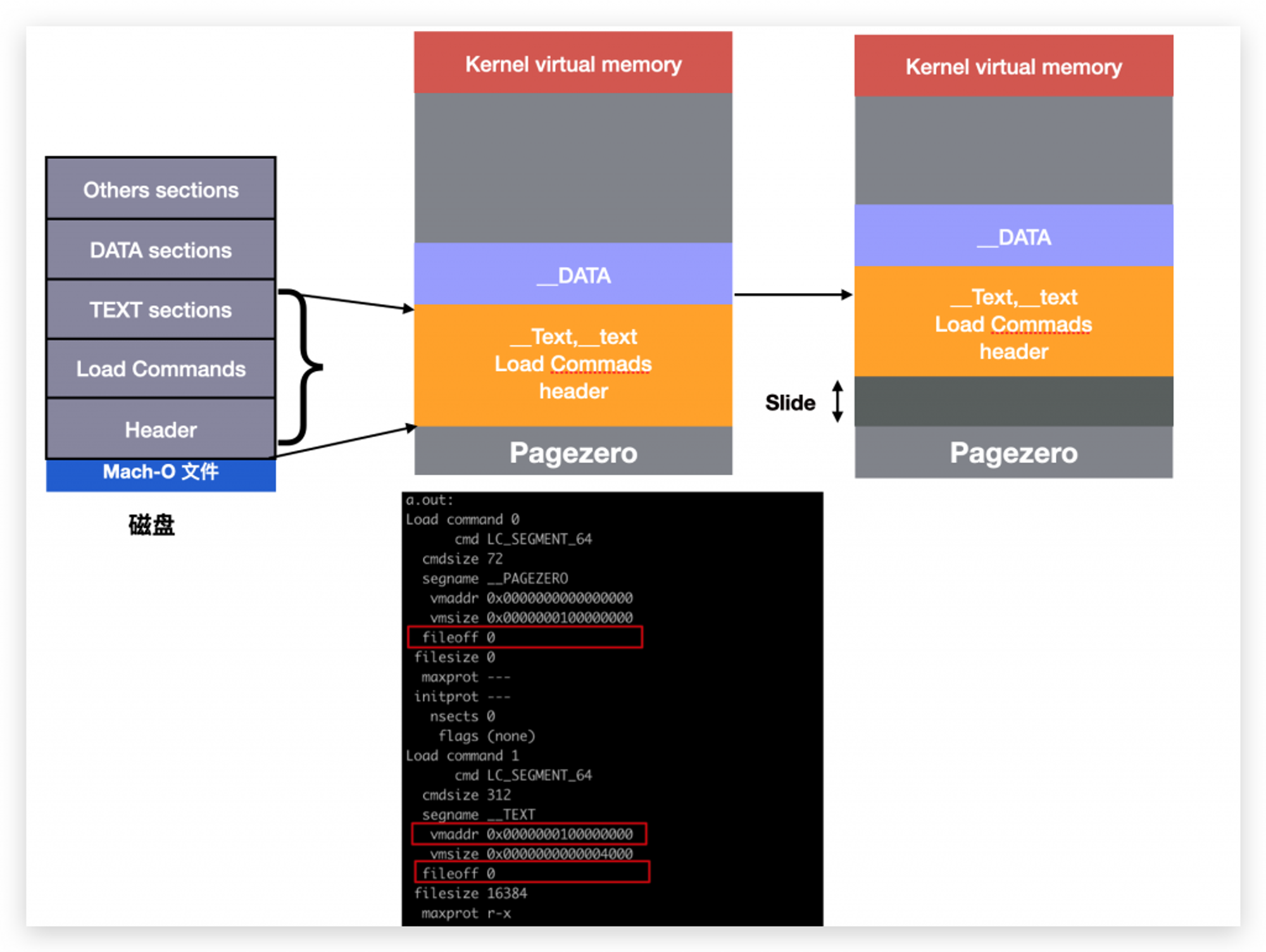
Pagezero
上图中,虚拟内存图示中,起始位置并不是 TEXT,而是
__PAGEZERO,这部分并不是占用真正的内存,只是在逻辑地址上占用一部分地址值。实际在代码中也是如此,在load_machfile中,等所有的虚拟内存都解析完成后,才进行了 Pagezero 的设置:#if __arm64__ if (enforce_hard_pagezero && result->is_64bit_addr && (header->cputype == CPU_TYPE_ARM64)) { /* 64 bit ARM binary must have "hard page zero" of 4GB to cover the lower 32 bit address space */ if (vm_map_has_hard_pagezero(map, 0x100000000) == FALSE) { vm_map_deallocate(map); /* will lose pmap reference too */ return LOAD_BADMACHO; } }
在64位机器上,Pagezero占了4GB的逻辑地址,也就是说,真正的TEXT起始的虚拟地址是
0x100000000,这是16进制 1 00 00 00 00,1 实际是处于地33位,也就是说,低32位全部置为0。__PAGEZERO一般都会有二进制文件进行指定:$ otool -v -l a.out Load command 0 cmd LC_SEGMENT_64 cmdsize 72 segname __PAGEZERO vmaddr 0x0000000000000000 vmsize 0x0000000100000000 fileoff 0 filesize 0 Load command 1 cmd LC_SEGMENT_64 cmdsize 712 segname __TEXT vmaddr 0x0000000100000000 vmsize 0x0000000000004000 fileoff 0
为了便于阅读,我删除了一部分字段,
segname __PAGEZERO中指定了vmsize 0x0000000100000000,但是同时又设置了filesize=0,并且fileoff字段和__TEXT的fileoff一样都是0 (fileoff 表示映射到虚拟内存中的本地文件的起始偏移值)。表示__PAGEZERO段没有任何数据,只是表示从虚拟地址 0-0x100000000 为__PAGEZERO的区域。该区域主要用来捕获空指针访问、等运行时的其他异常错误。具体作用如下:- 安全性:__PAGEZERO段的存在可以防止程序在运行时访问未初始化或未分配的内存区域。这有助于防止程序错误地读取或写入无效的内存,从而提高了程序的安全性和稳定性。
- 内存布局:__PAGEZERO段位于程序的起始位置,占用虚拟内存中的第一个页面。它的存在确保了程序的内存布局满足操作系统的要求,例如,在某些操作系统中,需要程序的代码段从一个特定的地址开始。
- 内存保护:__PAGEZERO段与其他段之间有一段未映射的空间,被称为"空洞"。这个空洞可以提供一种保护机制,使得在程序运行时,如果发生缓冲区溢出等内存越界访问错误,操作系统可以检测到并阻止对空洞区域的访问,从而减少潜在的安全漏洞。
dyld 与内存映像
当主程序被映射完成后,就会启动动态库加载器
load_linker。if ((ret == LOAD_SUCCESS) && (dlp != 0)) { /* * load the dylinker, and slide it by the independent DYLD ASLR * offset regardless of the PIE-ness of the main binary. */ ret = load_dylinker(dlp, header->cputype, map, thread, depth, dyld_aslr_offset, result, imgp); }
然后剩下的工作由 dyld 进行完成,dyld 主要是加载各个动态库,和建立主程序以及各个动态库的映像 Image。还有由于使用了地址空间布局随机,导致每个库内部的符号地址与出厂时不一致,所以需要修改(rebase)。动态库同样有自己的 slide 值(地址布局随机偏移值),同样需要rebase。这些事情都会由 dyld 来完成。
Image 映像
其实映像就是
ImageLoader抽象实例,具体使用的是ImageLoader的子类ImageLoaderMachO实例,子类实例还会细分为压缩格式和传统的非压缩格式。每个 Mach-O 文件,包括可执行文件和动态库,都会对应一个 Image 实例。Image 映像实例主要包含每个 Mach-O 的符号信息,以及符号绑定的相关信息:enum PrebindMode { kUseAllPrebinding, kUseSplitSegPrebinding, kUseAllButAppPredbinding, kUseNoPrebinding }; enum BindingOptions { kBindingNone, kBindingLazyPointers, kBindingNeverSetLazyPointers }; enum SharedRegionMode { kUseSharedRegion, kUsePrivateSharedRegion, kDontUseSharedRegion, kSharedRegionIsSharedCache }; struct Symbol; // abstact symbol struct DynamicReference { ImageLoader* from; ImageLoader* to; };
可执行文件的映像实例会第一个被加载,方便后边进行动态库相关的符号绑定。Image 中还包含Mach-O文件的虚拟地址的入口:
struct DOFInfo { void* dof; const mach_header* imageHeader; const char* imageShortName; };
基于此,我们可以运行时动访问每个Mach-O文件中的的内容。
const struct mach_header* image_header = _dyld_get_image_header(0) Dl_info info; if (dladdr(image_header, &info) != 0) { getsectbynamefromheader((void *)info.dli_fbase, "__DATA", "section_name"); }
映像 Image 是基于虚拟内存,而非 Mach-O 文件。所以使用时需要注意 slide 值,有些函数内部计算了
slide值,有些函数则没有计算,下面详细剖析这个 ASLR 的 slide 值。ASLR
ASLR(Address Space Layout Randomisation),地址空间布局随机,发生在程序每次装载的时候,也就是生成虚拟内存的时候,这么做主要是出于安全方面的考虑,让攻击者很难确定程序各个段的地址。具体来说,当程序生成虚拟内存的时候,会给每个segment加上slide值。
前边提到通过
getsectbynamefromheader等函数获取数据的时候,需要注意计算这个 slide 值。理论上slide = Load 起始地址 - Linker 起始地址。在cctools开源库中,苹果也有源代码展示了该值的计算方法。getsectiondata() { // ..... struct segment_command *sgp; intptr_t slide; slide = 0; sgp = (struct segment_command *)((char *)mhp + sizeof(struct mach_header)); if(strcmp(sgp->segname, "__TEXT") == 0){ slide = (uintptr_t)mhp - sgp->vmaddr; } // ..... }
在getsecbyname.c文件中,有些函数,苹果内部计算了 slide 后的真实地址,比如上边的
getsectiondata()函数,有些函数则没有计算,拿到的是链接时的虚拟地址,比如getsectdata()函数。比较费解的是,为什么
slide = mhp - sgp->vmaddr,mhp就是Mach-O的Header起始地址(Load 起始地址),sgp->vmaddr是TEXT段的起始地址(Linker 起始地址)。sgp->vmaddr作为链接时的起始地址比较好理解,因为该值是从Load Commands中读出来的,无论是链接时还是load时,这个值都是一个静态值,不会被修改,该值又指向了TEXT段的起始地址,TEXT总是会作为虚拟内存的第一个被Slide的段。那为什么Header会被当做Load时的起始地址? 原因是Header和Load Commands都会被映射进入
TEXT段,且放在最前边,也就说__TEXT,__text代码段并不是整个TEXT的起始地址。 这一点非常容易被忽略,导致好多文章中都没有能清晰的解释为什么 slide 值这样计算。事实上从Mach-O文件的Load Commands也能看到,TEXT的fileoff字段和__PageZero的fileoff都是0,fileoff表示,该段映射虚拟内存时,在Mach-O文件的起始偏移。0表示TEXT段从Mach-O文件的最开始进行映射,而 Mach-O 文件的最开始就是Header,然后是Load Commands,然后才是代码段__text。__PageZero则只占有一段固定的虚拟内存地址(0x100000000, 4GB),并不包含任何内容。所以:slide = (uintptr_t)mhp - sgp->vmaddr; // mhp: 真正的 Text 起始地址 (滑动后的, text 段以 header 起始) // sgp->vmaddr :0x100000000 Pagezero 结尾的下一个地址
动态虚拟内存与匿名映射(anonymous)
经常上边的一系列分析,程序启动,通过可执行文件,仅映射了
TEXT段和DATA段。而栈、堆虚拟内存区域则是运行时动态映射的。也称为匿名映射,即该虚拟内存区域并没有与之对应的磁盘文件,所以叫匿名映射,对应的系统调用函数是mmap,允许开发者映射自己的虚拟内存。栈区由函数的调用和返回,自动映射和回收。堆区,则是通过开发者的调用产生的映射,比如调用C语言的malloc()函数后,内核会立即在虚拟内需的堆区进行匿名映射,产生虚拟内存地址。但此时并没有真正的物理内存地址被占用。而是当真正访问这个堆区的虚拟内存时,才会由专门的堆分配器(Allocator)进行分配,由于Allocator只是快速的扫描空闲区,然后返回合适的物理内存地址,无需从磁盘中调页,所以这个过程会很快。 Allocator内部会基于各种算法,例如临近适应、首次适应等算法,进行堆内存的分配,Allocator一般式一个双向链表,且需要内存对齐,由于内存对齐,所以内存地址的低地址位在内核看来总是0,例如用4KB分页,那么内存地址总是0x1000的倍数,低12位总是0,这些位就会被用来存储该连续内存区域的大小,是否已分配,前驱结点,后继结点等信息。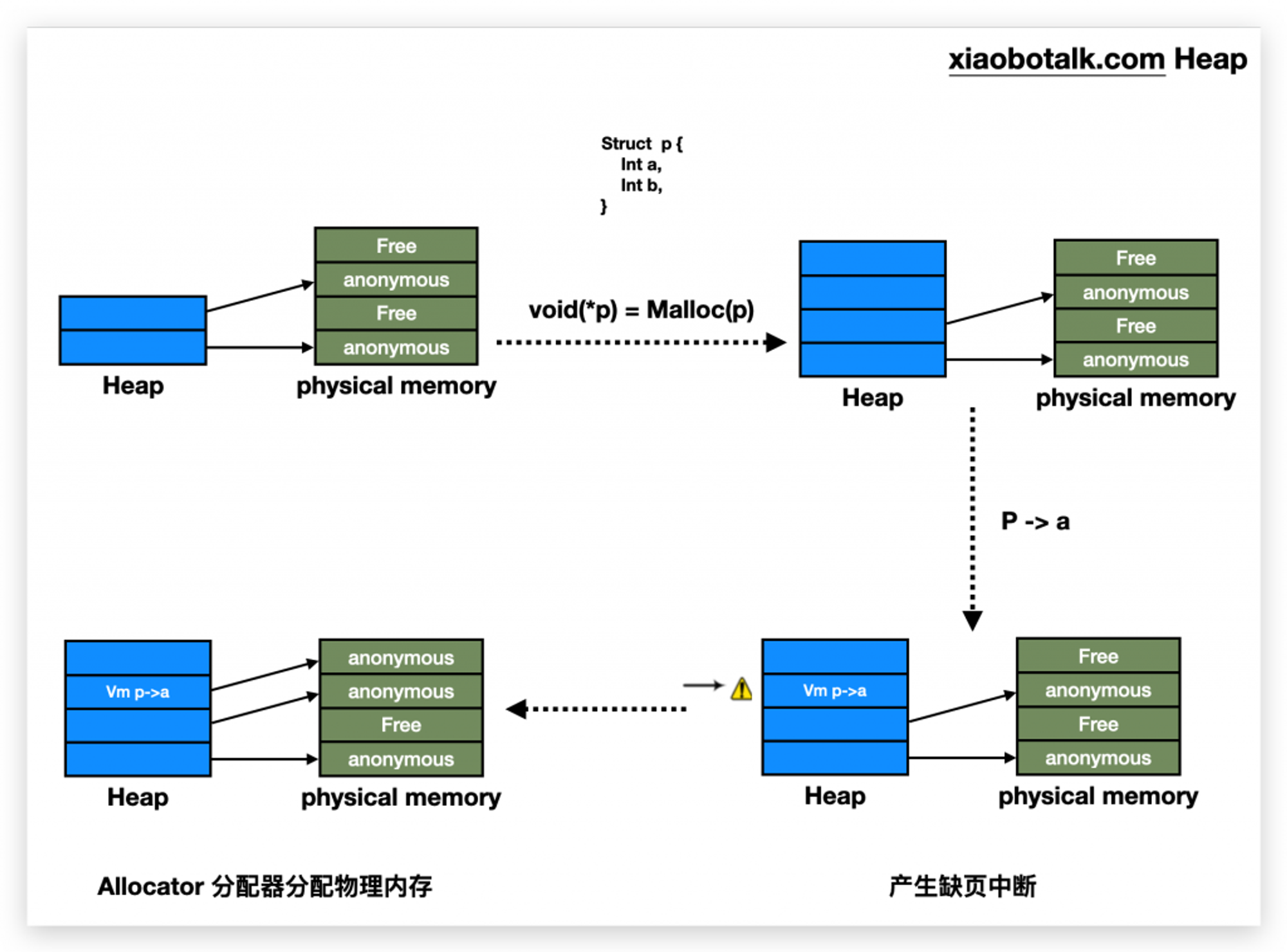
Copy On Write (COW)
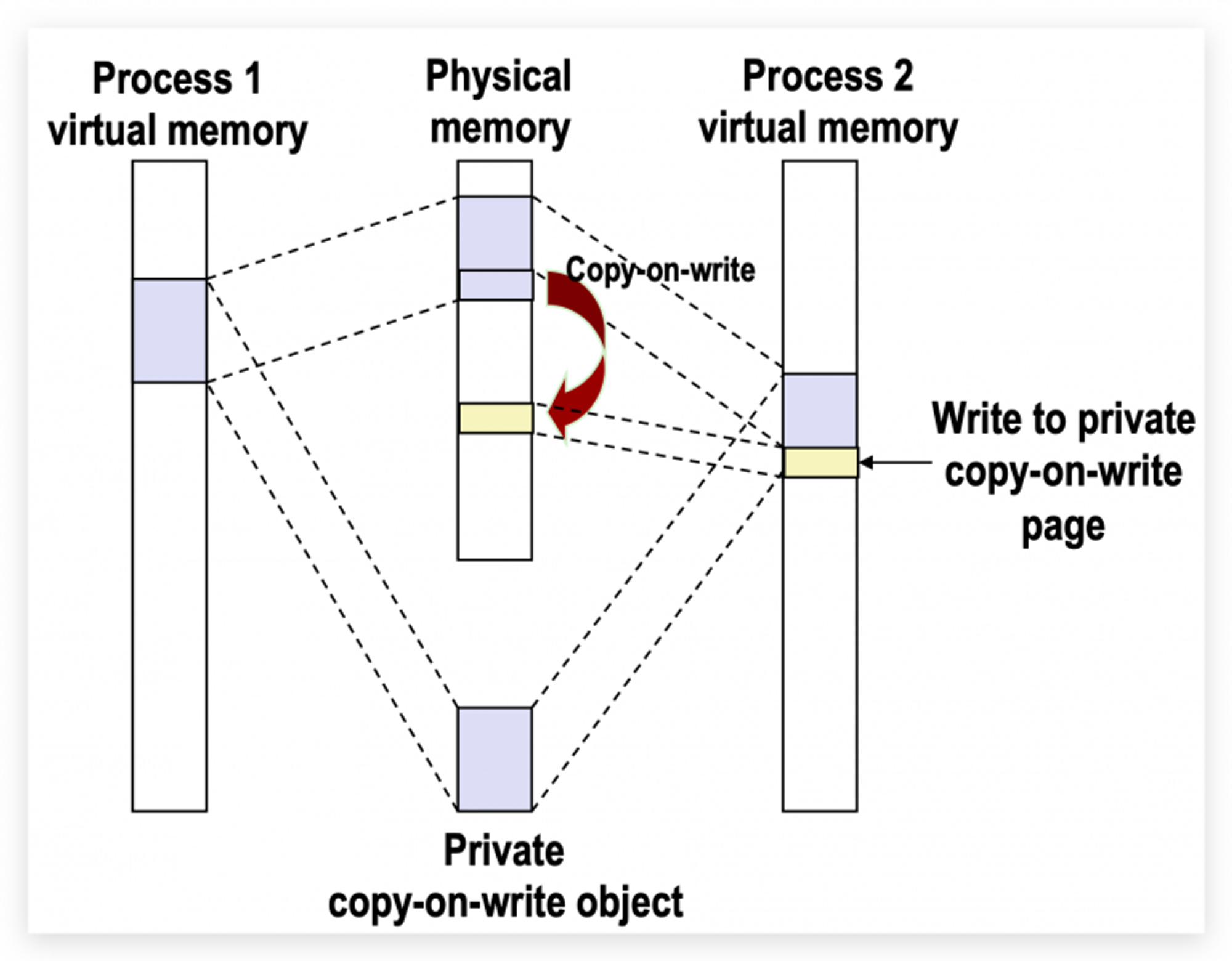
COW 写时复制,一般多用于共享数据或者动态库,例如创建了动态库,我们希望代码可以被多个进程共享,这样减少内存占用。 但是,有些进程可能需要对共享区的数据进行修改,那么该进程就需要自己持有一份单独的数据,发生内存拷贝。内核会尽量延迟这个拷贝,直到进程真正开始写入的时候。具体的做法是,通过虚拟内存区的
cow权限和页表的read-only权限共同作用,产生中断,内核处理中断,拷贝出需要修改的内存。 共享库在自己的页表中,总会设置该物理内存区域为read-only,而进程总会把需要修改的虚拟内存区域设置为copy-on-write(vm_page中的属性)。当进程执行修改数据指令时,会先经过页表查寻物理地址,此时页表中显示该物理地址区域为read-only,所以会产生非法写入中断,内核捕获这一中断,检查进程的虚拟地址权限是cow,则进行内存拷贝,但只会拷贝需要修改的内存页,修改进程的页表项,让进程的虚拟地址映射到拷贝后的物理内存块上。完成后,中断返回,重新执行修改指令。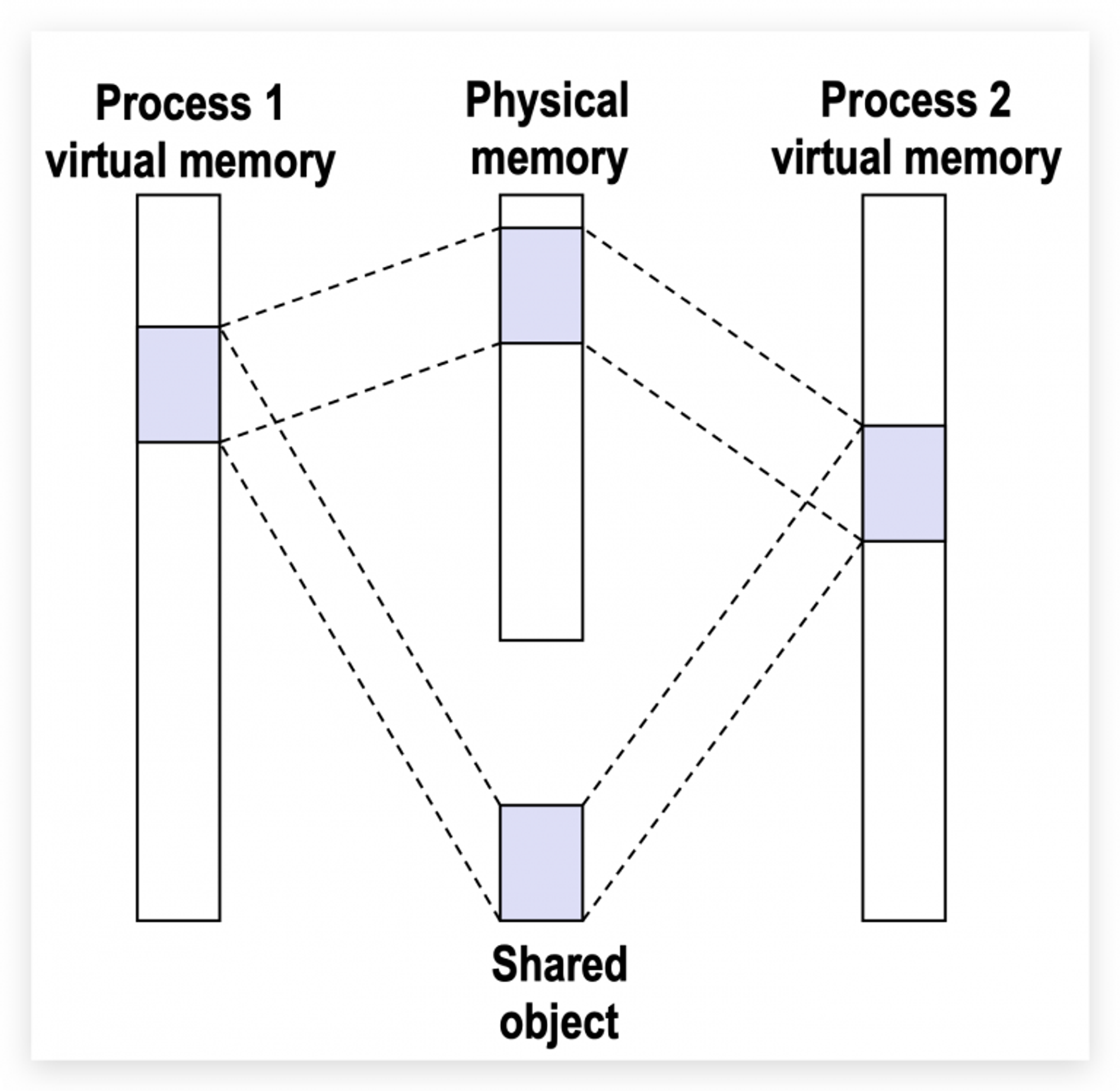
上一篇
参考
1、https://manybutfinite.com/post/how-the-kernel-manages-your-memory/ 2、xnu/dyld/cctools 源码。