翻译:Xiaobo 原文链接: Lock-free multithreading with atomic operations 推荐:之前读《程序员的自我修养》一书中有关于多线程的讲解非常好;但最近读到这几篇文章对于多线程的讲解,个人认为比前者(书)更加的清晰、易懂、全面。每篇文章的内容安排也很合理,非常感谢作者
TRIANGLES和他优秀的文章,这里是他的个人站点。相关系列译文
- 「译文」原子操作-无锁多线程编程 (本篇)
译文正文部分
在希腊语中,原子 (?τομο?; atomos) 的意思是不可切割。当计算机执行的每个任务无法再细分的时候(无法拆分为更小的子任务),这就是一个原子的任务。
在多线程编程中,原子是一个重要的属性:因为原子操作不可再细分,一个线程就无法闯入到另一个线程正在执行的原子操作中。假如,写入数据操作是原子的,那么其他线程就无法在另一个线程写入未完成的时候进行数据读取。反过来,读取数据也一样。换句话说,原子操作中,不存在数据竞争。
前一篇内容中,已经介绍了所谓的同步原语的概念,还有常见的实现线程同步的工具。它们也经常被用来在多线程中提供原子操作。但实现的方式仅仅是让单线程访问,阻塞其他线程,直到第一个线程完成操作。基于它们有能力冻结线程,同步原语也被称为阻塞机制。
前一篇提到的阻塞机制,在大部分情况下都能很好的工作。只有使用正确,它们也是可靠和快速的。然后,它们也有一些缺点需要注意:
1、休眠的线程除了等待,什么也做不了。 2、它们可以挂起你的应用程序–如果一个持有同步原语锁的线程由于某种原因崩溃,锁本身将永远不会被释放,等待的线程将永远被卡住; 3、开发者无法控制哪些线程将被休眠–一般这是被操作系统控制的,这就有可能引发优先级反转:执行重要任务的线程被迫等待那些执行不重要任务的线程。
大部分情况下,你可能也不会关心这些问题,因为它们似乎不会影响程序执行的正确性。但也有可能,为了充分利用多核 CPU,让一些线程一直保持运行也是可行的,此时如果因为优先级反转而引起系统假死,这就是个大问题了。
无锁编程
好消息是:我们还有其他方式控制多线程的并发任务。这个方式就是无锁编程,这是一种不使用锁机制来保证多线程安全的技术。
坏消息是:这是一种很底层的方式,这种方式,离硬件更近了一步。同时,使用无锁编程是对自己的智力挑战,也是我们了解计算机到底如何工作的好机会。
无锁编程依赖原子指令,这些原子指令是直接被 CPU 执行的。所以,我们需要先了解一些原子指令,然后我会告诉你如何使用这些执行进行并发控制。
什么是原子指令
当计算机显示一张图片到屏幕上的时候,实际上是由若干子任务组成:从存储单元中读取图片,解码图片,渲染像素点等等…,如果我们再放大每个子任务去看,每个子任务又能划分出更多的子任务。一直拆分到最小,对人类可见的被处理器直接执行的操作叫“机器指令”。下图中,虚线框属于软件层,实线框属于硬件层:
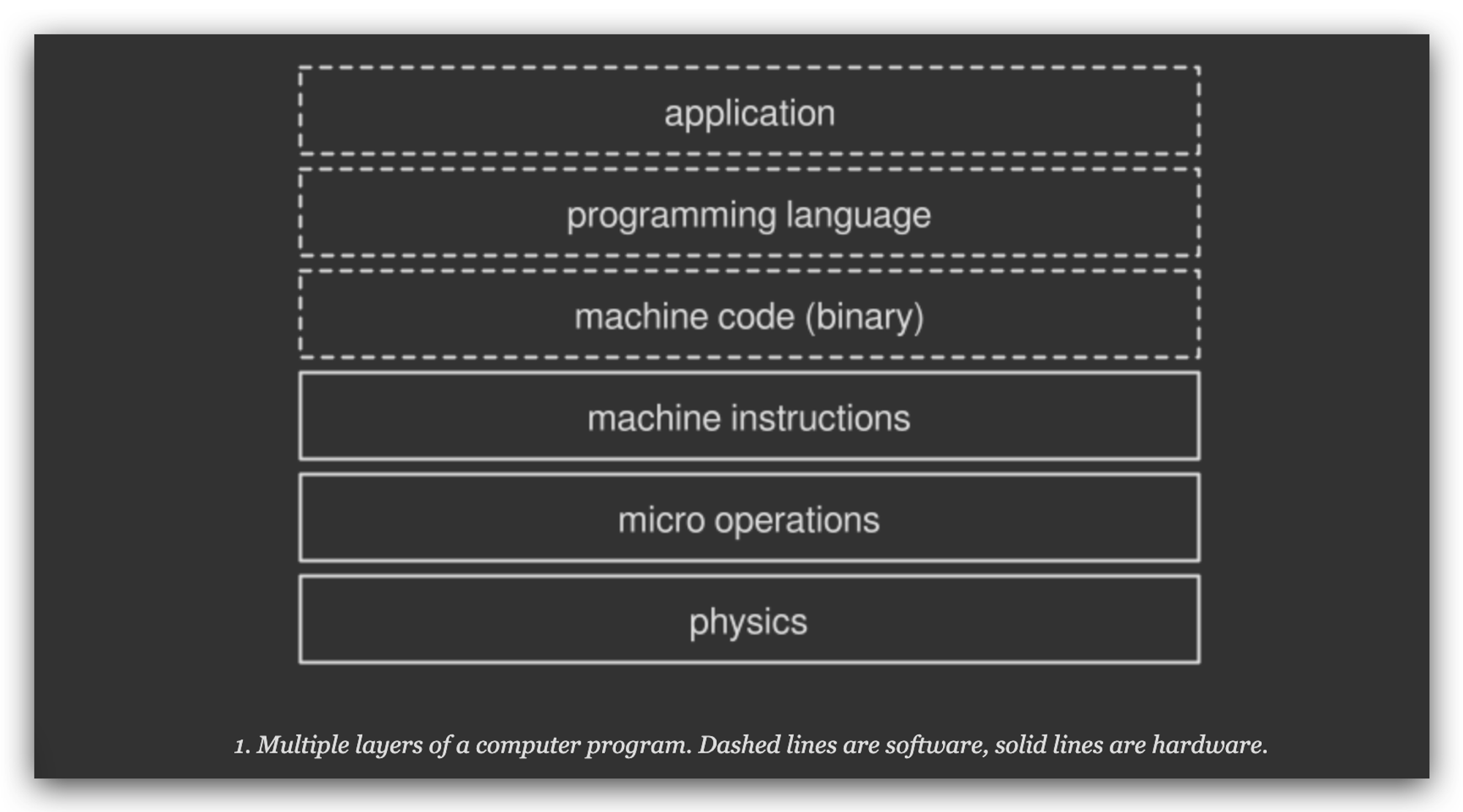
不同的 CPU 架构中,都有各自不同的机器指令,其中有些机器指令是原子的,这些指令的执行是单独的,不能分割,也不能被打断。也有一些指令不是原子的:这些指令在执行的时候,会被处理器在划分为多个更细微的操作在后台执行,也被称为微操作(micro-operations) ;我们暂时把焦点放到前边那一类,即原子指令上。原子指令可以分类两个大类:
1、存储/装载指令 (store-load) 2、RMW 指令 (read-modify-write)
存储装载原子指令 (store-load)
这些指令被用来从内存中存储和读取(装载)数据。大多数的 CPU 架构在设计时,都会确保这些操作在一些特定情况下是原子操作。比如基于 X86 架构实现的处理器,都会有
MOV指令,用来从内存中读取字节数据交于 CPU,如果对字节对齐(aligned data) 的数据执行MOV操作,CPU 就会确保该操作是原子的。(aligned data:存储在内存中的信息,方便CPU轻松快速的读取)。RMW (read-modify-write) 原子指令
一些复杂点的操作,仅仅通过存储和读取是无法完成的,比如自增操作(++x),至少需要 3个存储和读取的原子指令,这就会整个操作变的非原子化 。RMW 原子指令正是用来填补这种问题,它能让多次复杂操作变为一整个原子操作。这类指令非常多。一些 CPU 架构实现了它们,主要的分类如下,其他的都是这些指令的子集:
1、test-and-set 原子指令:将某个值写入内存中的某个位置并返回旧值,整体发生在一个原子步骤中。
2、fetch-and-add 原子指令:递增内存中的某个值并返回旧值,整体发生在一个原子步骤中。
3、compare-and-swap (CAS) :用给定的值比较某个内存地址中的值,如果相等,就修改内存中的值为另一个新值。
上述这些在内存中的执行了多个任务的指令都是原子操作。RMW 指令的这一原子特性很适合完成无锁多线程操作。
原子指令的 3个层次
上述所有的指令都属于硬件操作:这些指令直接和硬件打交道。这些指令使用起来也不是很方便,有些指令在不同的 CPU 架构下命名也可能不同,有些甚至指令可能在不同的处理器版本上被阉割。所以,开发中你可能不会用到这些指令,除非你真的需要为具体的 CPU 架构做一些底层工作。
上升到软件层面来看,许多操作系统都提供了各自的原子指令。我们称为原子操作 ,这些操作都是从物理的机器指令中抽象而来。比如,Windows 下的
Interlocked API:提供了一组函数通过原子的方式操作变量。MacOS 的 OSAtomic.h 的头文件也能看到类似的函数。这些函数都隐藏了具体的硬件实现,仍然只能在各自的环境(具体的操作系统下)中使用。执行原子操作的最佳方式,还需依赖于编程语言。比如,JAVA 中有
java.util.concurrent.atomicjar 包;C++ 提供了std::atomic头文件;Haskell 的Data.Atomics包以及其他语言中的原子操作库。一般来说,如果一种编程语言支持多线程编程,很大可能它也会提供原子操作的相应封装。你可以通过编译器(如果是编译语言)或者虚拟机(如果是解释语言)来帮助找到实现原子操作的最佳指令,或者通过底层的操作系统 API 或者直接通过硬件。原子指令的 3个不同层次,虚线代表软件层,实线代表硬件。
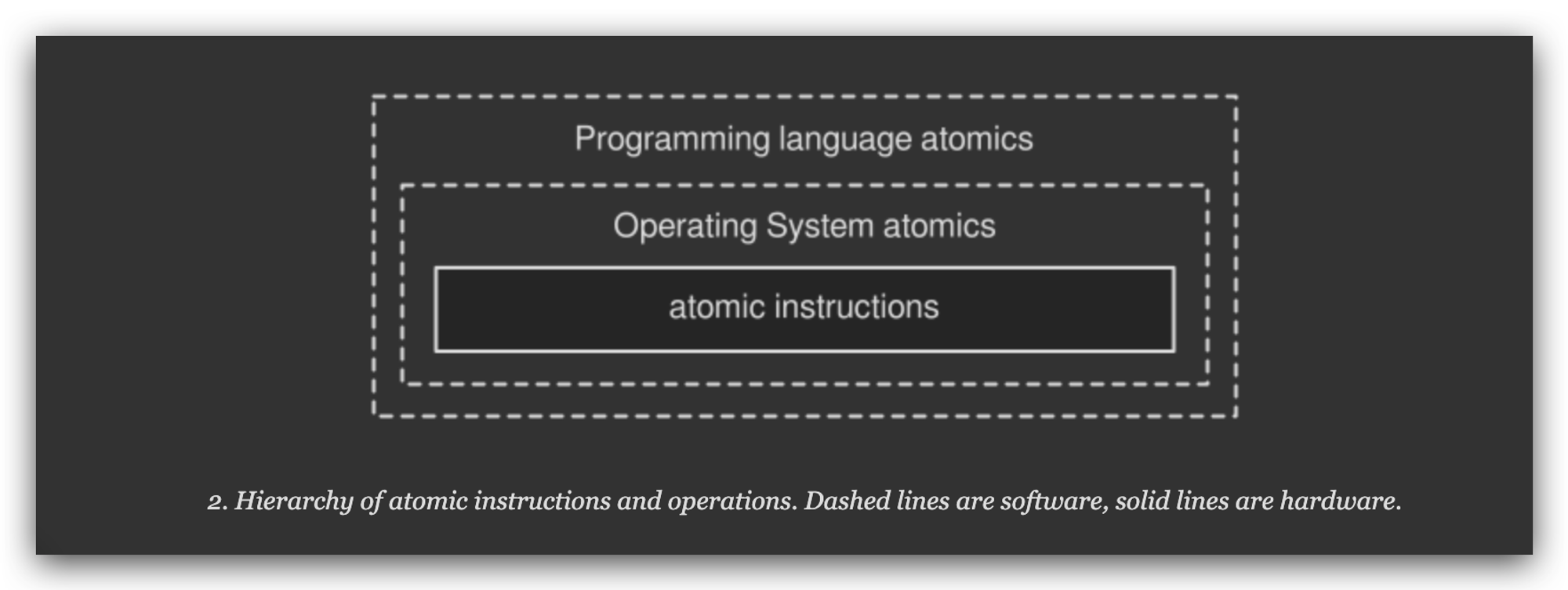
例如,C++ 的 GCC 编译器,通过会直接将 C++ 中的原子操作和对象转换为机器指令。编译器也会在可行的情况下,将一些无法直接对应到硬件指令的特殊操作用相近的机器指令代替。最差的情况:底层硬件平台不能提供对应的原子操作,编译器就会用其他的阻塞策略代替,当然,这样就不能称为无锁了。
在多线程中使用原子操作
下面通过一个变量自增的(x++)例子,来演示如何使用原子操作:
x++;
自增操作本身就不是原子操作,它有 3步组成:
1、读取 x 的值 2、进行 +1 操作 3、存储新值
一般情况,你可能通过互斥锁来确保操作安全(伪代码):
mutex = initialize_mutex() x = 0 reader_thread() mutex.lock() print(x) mutex.unlock() writer_thread() mutex.lock() x++ mutex.unlock()
这样,第一个线程获得锁,进行相应的操作,其他线程则等待着锁的释放。
如果使用无锁的原子操作则是另外一种情形–线程可以无阻碍的自由执行:
x = 0 reader_thread() print(load(x)) writer_thread() fetch_and_add(x, 1)
假定,
fetch_and_add()和load()都是和硬件指令对应的原子操作。你可能注意到,上述代码中没有用到锁。多线程可以自由的并发访问这两个函数。原子操作load()确保了没有读取线程会读取到一个不完整的值。同样fetch_and_add()确保了写入是完整的。实际编程中原子操作的问题
上边的例子展示了原子操作的一个重要特性:它们只处理原始类型–布尔、char、short、int等等。另一方面,实际程序需要对更复杂的结构(如数组、向量、对象、数组向量、包含数组的对象等)进行同步。如何用基于基元类型的简单操作保证复杂实体的原子性?
无锁编程中强调,我们需要跳出平常使用的同步原语的条条框框。原子操作与互斥锁或者信号量不同,它不会直接的保护共享资源。相反,它基于原子操作构建无锁算法或无锁数据结构,以确定多个线程将如何访问共享数据。
例如,前面看到的
fetch_and_add操作可以用来生成一个基本的信号量,然后,你可以基于它来调节线程。实时上,所有传统的、阻塞的同步实体都是基于原子操作实现的。人们已经写了无数的无锁数据结构或者算法,比如Folly’s AtomicHashMap、Boost.Lockfree library、多消费者-生产者队列FIFO queues、read-copy-update(RCU)算法等。从零开始编写这些原子武器是很困难的,更不用说让它们正常工作了。这就是为什么大多数时候你可能想要使用现有的,经过反复测试的算法和结构,而不是自己实现。
compare-and-swap (CAS) loop
实际的应用中,compare-and-swap (CAS) loop 可能是无锁编程中最常用的策略。它基于compare-and-swap原子操作,支持多线程写入。特别是在一个复杂的系统中去使用并发算法的时候,这是一个重要的特性。它在无锁代码中引入了循环模式,以及一些理论概念。让我们更进一步的观察它。
A CAS loop in action
操作系统或者编程语言可能会提供一些 CAS 函数:
boolean compare_and_swap(shared_data, expected_value, new_value);
函数有 3个入参:共享数据的指针,预期值(共享数据的预期值),和要修改的新值。当
shared_data.value == expected_value的时候,说明共享数据的值没有被其他线程修改,此时共享数据的值会被修改为新值new_value,函数返回true表示修改成功。在多线程并发操作下,compare_and_swap 函数很有可能返回
false,CAS loop 就是通过循环调用 compare_and_swap 函数,直到操作成功。如果一个线程通过 CAS 修改共享值时,同时有另外一个写入线程修改了共享值,CAS 函数就会返回false,返回false的原因是shared_data.value != expected_value。我们用 CAS loop 改写前文的
fetch-and-add的例子,大致如下:x = 0 reader_thread() print(load(x)) writer_thread() temp = load(x) // (1) while(!compare_and_swap(x, temp, temp + 1)) // (2)
写入操作调用了循环的调用
compare_and_swap,直到函数返回true。交换范式
正如前边所说,CAS loop 通过引入循环的方式,给许多算法提供了无锁编程。
1、先为 shared data 拷贝一份本地副本。 2、根据上下文,修改本地副本为预期值。 3、准备好后,通过将共享数据与之前创建的本地副本交换来更新共享数据。
步骤 3 是关键:交换是通过原子操作完成的。这样确保了,当一个线程在写入的时候,另一个线程只能监听到两种值,要么是写入之前的旧值,要么是写入完成的新值。不会有中间的脏数据产生。
这种方式在哲学上就和加锁机制区别开了:无锁算法的多线程只有在同时遇到一小段原子操作时,互相有干扰,其他大部分时间,都在无意识、不受干扰的独立运行着。也就是说多线程的互相影响被缩小到最小的原子操作期间。
优雅的使用锁的方式
像上边这种(CAS loop),通过循环去等待原子操作完成的策略来实现的无锁算法被称为自旋锁:线程通过一个简单的循环(loop)不断的重复尝试执行,直到执行成功。这种机制优雅的地方在于,线程不会被操作系统强制睡眠,而是一种在运行,直到循环结束。相反,通过互斥机制和信号量实现的常规的锁,则更加昂贵,因为不停的挂起和唤醒线程需要很大的CPU 运算开销。
ABA 问题
在来回顾一下前边的代码:
writer_thread() temp = load(x) // (1) while(!compare_and_swap(x, temp, temp + 1)) // (2)
上述代码的
(1)和(2)两处,确实是原子操作,但是有问题的:很有可能另一个线程会在(1)和(2)的中间裂缝中插入执行,会引发著名的 ABA问题,ABA问题是无锁编程的常见问题。基本表述为:- 进程 P1读取了一个数值A
- P1被挂起(时间片耗尽、中断等),进程P2开始执行
- P2修改数值A为数值B,然后又修改回A
- P1被唤醒,比较后发现数值A没有变化,程序继续执行。
对于P1来说,数值A未发生过改变,但实际上A已经被变化过了,继续使用可能会出现问题。在CAS操作中,由于比较的多是指针,这个问题将会变得更加严重。事实上,造成 ABA 问题一大原因就是内存重用机制造成的,具体可看维基百科 CAS。大部分情况下你可以不关心 ABA 问题,但一旦发生了,就很难发现,好在还是有解决方案的。
CAS loop 可以用来交换任何值
CAS loop 经常被用来交换指针变量,特别是用来修改类或者数组这种复杂数据结构的时候很方便:只需创建本地副本,根据需要对其进行修改,然后在准备好时将指向本地数据的指针与指向全局数据的指针交换。这样全局数据将指向为本地副本分配的内存,其他线程将看到最新的信息。
这个技术允许你成功的同步非基本数据实体,但是很难确保正确的工作。如果在交换之后,读线程仍然在读取旧指针呢?如何正确删除前一个副本而不生成危险的悬挂指针? 再一次,工程师们找到了许多解决办法,比如垃圾回收(garbage collection) 、引用技术(reference counting) 、epoch-based memory reclamation 、 hazard pointers。
Lock-freedom vs. wait-freedom
每一种通过原子操作实现的数据结构或算法都可以归为两类:lock-free 或 wait-free。当必须评估基于原子操作的工具对程序性能的影响时,这是一个重要的区别。
Lock-free 算法允许线程继续有效的工作即使当其中的一个线程处于短暂的忙碌中。换句话说,至少有一个线程总是运行的。CAS loop 就是 lock-free 的完美案例,因为如果一个 CAS loop 返回 false ,则表示有其他线程成功的修改了值。但 lock-free 算法很容易造成大量不可预测的空循环,特别是当有许多线程在竞争同一个资源的时候。将问题极端化后,使用CPU资源的无锁算法的效率可能远远低于使阻塞线程进入睡眠状态的互斥锁。
Wait-free 算法,是 lock-free 算法的一个子集。在 wait-free 算法中,无论其他线程的执行速度或工作负载水平如何,任何线程都可以以有限的数量或步骤完成其工作。文章开头提到的
fetch-and-add原子操作就是基于 wait-free 算法实现的:没有循环,没有重试。同时,wait-free 算法也具有容错性(fault-tolerant):任何线程都无法通过其他进程的失败或其速度的任意变化来阻止其完成操作。这些特性使得无等待算法适用于复杂的实时系统(real-time systems),在其中并发代码的可预测行为是非常重要的。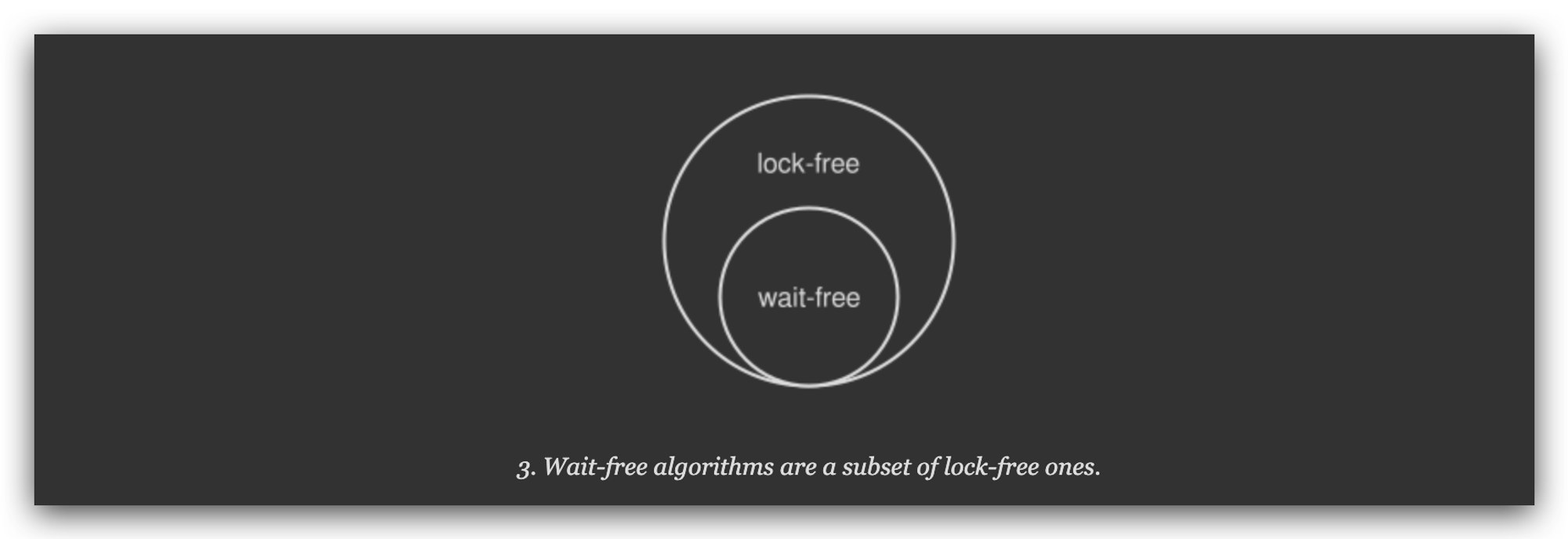
Wait-free 是并发代码的一个非常理想的属性,但是很难获得。总之,不管是在构建一个阻塞、一个无锁或一个无等待的算法,黄金法则是始终对代码进行基准测试并测量结果。有时,一个好的旧互斥体可以胜过更高级的同步原语,特别是在并发任务复杂度很高的情况下。
结尾语
原子操作是无锁编程的必要组成部分,即使在单处理器机器上也是如此。如果没有原子性,线程可能会在事务的中途中断,从而导致不一致的状态。在本文中,我只触及了一个表面:只要向方程中添加多核/多处理器,就会出现一个新的问题世界。顺序一致性(sequential consistency)和内存障碍等主题是这个难题的关键部分,如果您想从无锁算法中获得最佳效果,就不能忽略这些主题。我会在下一篇博客中介绍它们。
(译文完)